안녕하세요. AI 학습을 위해 GPU가 굉장히 많이 필요하다는 말은 뉴스에서 들어보셨을 겁니다. GPU를 여러 개 사용한다는 게 실제로 무슨 의미인지, 그리고 왜 그렇게까지 GPU를 여러 개 사용해야 하는지, 그리고 실제로 인공 신경망 모델 계산에서 GPU를 어떻게 여러 개 사용할 수 있는지 알아보겠습니다.

여기 2022년에 출시된 4000만원짜리 Nvidia H100 GPU가 있습니다. 이 엄청나게 비싼 GPU로 얼마나 좋은 AI 모델을 실행시킬 수 있을까요? 한번 알아봅시다.
AI 모델은 기본적으로 파라미터라는 값으로 이루어져 있습니다. 뉴런 사이를 잇는 시냅스의 가중치와 바이어스 같이 학습을 통해 얻을 수 있는 값을 의미합니다. 파라미터의 개수와 자료형에 따라 모델의 크기가 결정되게 됩니다.
어떤 프로그램이든 실행시키기 위해서는 메모리에 데이터가 있어야 합니다. 이 GPU의 메모리는 사진에서 보이듯 80GB입니다.
메타에서 출시한 가장 최신 LLM인 LLaMA 4 Maverick 모델의 파라미터 수는 4000억개입니다. 이를 전부 double 형으로 저장하게 되면 8바이트 * 4000억 = 3.2 테라바이트가 될 것입니다. 이를 H100에 일단 올려서 최신 모델 하나만 구동하려 해도 3.2T/80G = 40개, 16억원이 필요하겠네요.
다행히 모델의 크기를 줄이는 방법들이 많이 연구되고 있습니다. 대표적으로 자료형을 double이 아니라 더 작은(정밀도가 낮은) float 형으로 저장하는 방법이 있죠. 최근에는 극단적으로 1바이트(FP8), 0.5바이트(FP4)까지 크기를 줄이는 경우도 있습니다.
실제 서비스에서는 이렇게 정밀도를 낮춰 저장하기 때문에 훨씬 적은 용량의 RAM으로도 LLM 구동이 가능합니다. 하지만 이 모델의 모든 파라미터를 FP8로 저장한다고 해도 최소한 400GB의 RAM이 필요하니 여기서는 다중 GPU 시스템이 필수적이죠.
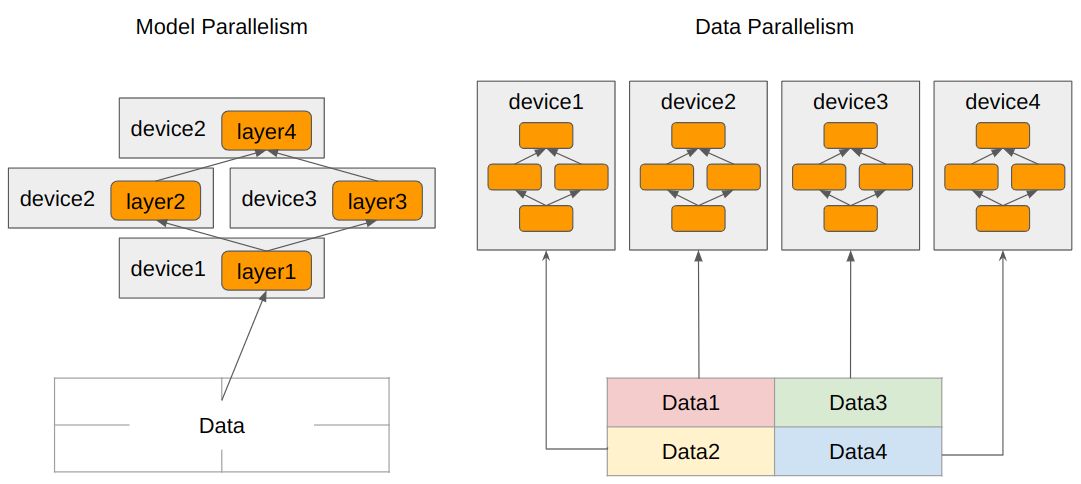
신경망 연산에서 GPU를 여러 개 사용한다는 것은 모델 파라미터와 데이터를 여러 GPU를 사용해 처리, 저장하겠다는 것입니다. 이를 병렬화 (Parallelism)이라고 하고, 병렬화 방법에는 위 그림[1]과 같이 크게 DP(Data Parallelism), MP(Model Parallelism)가 있습니다.
DP는 모델을 복사해서 여러 GPU에 저장하고, 입력 데이터를 나눠서 여러 GPU로 입력하는 방식입니다. 같은 모델 여러 개를 이용해서 데이터를 처리하면서 속도를 높이게 됩니다. 하지만 이 방식은 모델을 복사하기 때문에 메모리를 절약하진 않습니다.
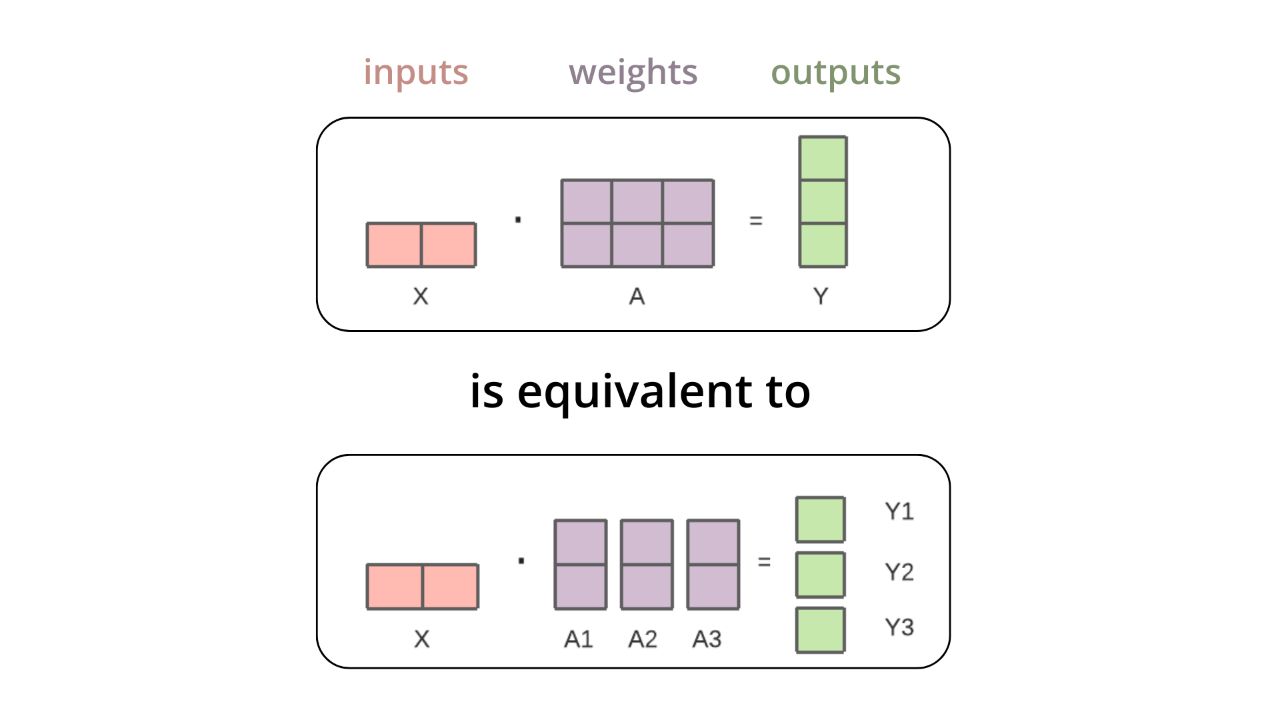
TP(Tensor Parallelism)와 PP(Pipeline Parallelism)는 모델을 나누는 Model Parallelism의 일종입니다. TP는 위 사진[2]과 같이 행렬, 벡터 연산을 나눠서 처리해도 결과가 똑같다는 점을 이용해서 여러 GPU에 모델을 나눠 저장하고 처리하게 됩니다. 모델을 나누게 되니 자연스럽게 GPU 하나에 필요한 메모리 용량이 줄어들며 병렬화로 인해 속도가 상승하게 됩니다.

PP는 컴퓨터 구조 시간에 배우는 파이프라이닝의 개념과 똑같습니다. 모델의 layer를 순서에 따라서 나눠 여러 GPU에 저장하고, 이전 layer가 있는 GPU에서 다음 layer를 저장한 GPU에 결과를 전송하게 됩니다. 이 과정에서 데이터를 마이크로배치로 나누고 스케쥴링을 잘 활용해, 연산과 통신을 최대한 겹쳐 bubble, 즉 쉬는 GPU를 줄이는 것이 PP의 핵심이 됩니다.[3]
위에서 설명한 다양한 병렬화 방법으로 다중 GPU AI 연산을 할 수 있습니다. 그런데… 중요한 점을 빼먹었습니다. 각 GPU에서 나온 결과를 어떻게 다시 하나로 합치죠? 나눠서 계산한 결과가 모델 하나일 때와 동일해야 할텐데요. 그리고 만약 신경망을 학습시킬 거면 forward만 아니라 backward도 생각해야 합니다.
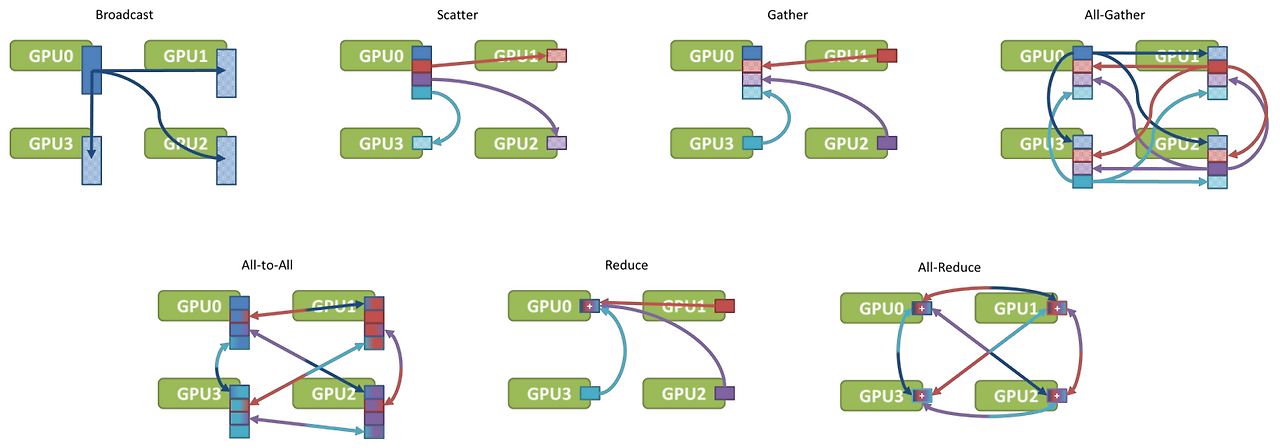
멀티 프로세스에서 한 그룹의 프로세스가 동시에 통신하는 패턴을 집합통신(Collective Communication)이라고 합니다. 집합통신에서 각 프로세스, 일반적으로 각 GPU에 할당된 번호를 Rank라고 하고 주고받을 데이터 조각을 Chunk라고 합니다. 집합통신에는 위 그림[4]과 같은 종류들이 있습니다.
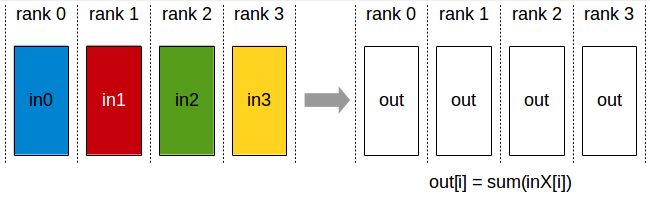
인공 신경망에서 가장 많이 쓰이는 통신 패턴은 All-Reduce로 모든 rank에 있는 데이터를 하나로 줄여(더하기, 평균, 빼기 등등… 입력 여러 개가 출력 하나로 크기가 줄어드는 연산들이면 다 가능합니다) 모든 rank가 결과를 공유하는 통신입니다. 이외에도 다양한 집합통신 패턴이 있습니다. 가장 널리 쓰이는 엔비디아에서의 구현을 보려면 NCCL[5]의 설명을 보시길 바랍니다.

Data Parallelism에서 집합통신이 어떻게 사용되는지 봅시다[4]. Forward path에서는 한 GPU가 가지고 있는 데이터를 여러 GPU로 분산(Scatter)하고, 모델을 Broadcast하게 됩니다. 그리고 각 GPU에서 각자 결과를 계산한 다음 다시 한 GPU로 결과를 모아(Gather) 최종 결과를 내죠.
Backward에서는 그래디언트를 이용해 파라미터를 업데이트해야 합니다. 한 GPU에서 loss의 그래디언트를 계산합니다, 이후 모든 GPU로 forward 단계에서 전달했던 데이터와 관련된 그래디언트를 scatter하여 각 GPU에서 다시 새로운 그래디언트를 계산합니다. 이를 다시 한 GPU로 모아 그래디언트의 평균값(Reduce 결과)을 얻을 수 있습니다. 이 평균 그래디언트를 이용해서 모델을 업데이트하면 완료됩니다.
MP에서도 데이터를 모아야 하지만 이는 분량상 생략하도록 하겠습니다.

GPU 한 대에서 여러 GPU에 데이터를 분배하고 다시 모으는 방식은 채널 대역폭 제한과 GPU 연산량 문제로 매우 비효율적입니다. 때문에 실전에서는 위[5]처럼 Ring All-Reduce라는 방식을 주로 사용합니다. 실제로 Ring All-Reduce는 대부분의 네트워크에서 optimal(대역폭 관점에서)에 가까운 성능을 낸다고 알려져 있습니다.

Ring All-Reduce 알고리즘의 또다른 장점은 네트워크 토폴로지(모양)과 관계없이 논리적인 Ring을 만들 수 있다면 연산이 가능하다는 것입니다. Nvidia의 최신형 GPU 서버는 위[3]와 같이 Tree 형태의 토폴로지를 가지고 있는데 여기서도 Ring을 쉽게 연결할 수 있습니다.
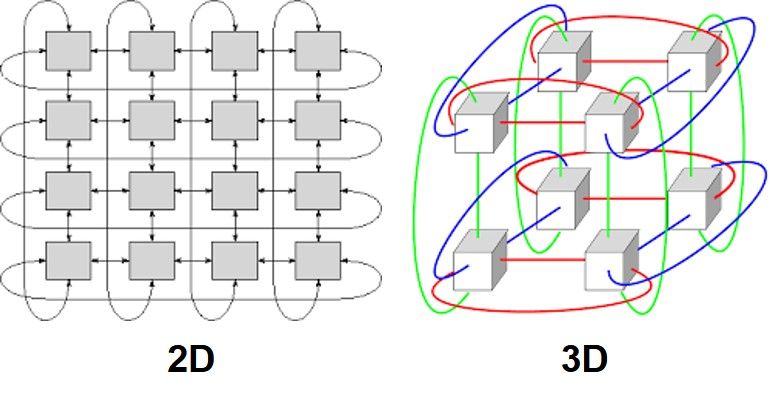
구글의 TPU는 이렇게[6] 2D, 3D Torus 토폴로지를 사용하는데 이는 1D Ring을 다차원으로 확장한 토폴로지이기 때문에 마찬가지로 Ring 구현이 간단한 편입니다.

현재 분산학습에서의 병목은 All-Reduce에 걸리는 시간이 대부분입니다. 때문에 위의 Nvidia 네트워크 홍보자료[7]를 보면 Bisection Bandwidth (네트워크를 반으로 잘랐을 때 단면을 지나는 대역폭)와 함께 All-Reduce의 속도도 함께 표기하는 모습을 볼 수 있습니다.
이렇듯 여러 GPU를 이용해 어떻게 거대한 인공신경망을 병렬처리, 분산학습 하는지 메모리, 통신 관점에서 살펴보았습니다. 모델의 크기가 점점 거대해지고 필요한 GPU 개수도 open ai에서 얼마 전에 GPU 1억대를 가지는 것이 목표라고 할 정도로 많아지고 있죠.
그에 비해 통신 속도, 메모리 대역폭과 크기는 맞춰 따라가고 있지 못하고 있으므로 집합 통신의 효율성은 점점 더 중요해질 것입니다. 이를 해결하고 싶다면 “인터커넥션 네트워크” 같은 분야나 “MPI”, “NCCL” 같은 집합통신 라이브러리 등을 살펴보시길 바랍니다!
[1] https://docs.pytorch.org/torchrec/high-level-arch.html
[2] https://huggingface.co/docs/text-generation-inference/conceptual/tensor_parallelism
[3] https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
[4] https://www.linkedin.com/pulse/ring-allreduce-distributed-machine-learning-shubhmay-potdar
[5] https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html
[6] https://www.nextplatform.com/2018/05/10/tearing-apart-googles-tpu-3-0-ai-coprocessor/
[7] https://hc34.hotchips.org/assets/program/conference/day2/Network%20and%20Switches/NVSwitch%20HotChips%202022%20r5.pdf