https://arxiv.org/abs/2505.09343
올해 가장 재밌게 읽은 논문 중 하나다. 보통 Technical Report 논문들 보면 모델 아키텍처랑 성능 쪽에 초점을 맞춘 경우가 많은데 이렇게 하드웨어, 통신을 집중적으로 파고든 논문은 찾기 어려웠다.
DeepSeek는 뉴스에도 여러 번 나왔다시피 수출 규제 때문에 성능에 제한이 있는 H800 2048대만으로 학습을 진행했다. 이 정도 스케일도 한국에선 따라하기 어렵지만 덕분에(?) FP8 학습, 새로운 토폴로지 (Multi Plane Fat Tree), Model-Hardware Co-design, 더 많은 expert가 있는 MoE, DeepEP, DualPipe 같은 새로운 통신 라이브러리, Node-Limited Routing 같은 온갖 기법들이 쏟아져나왔다.
DeepSeek-V3가 처음 발표되었을 때 더 이상 GPU가 많이 필요 없다고 엔비디아 주가가 폭락했었다. 지금 주가를 보면 알겠지만 완전히 기우였다. 당연히, 저 기법들을 쓰면서 좋은 GPU를 같이 쓰면 효율은 배가 된다.
아무튼 이런 걸 논문으로 과감하게 풀어버리는 건 대학원생한테는 축복이다.
모델 아키텍처와 성능 같은 내용은 Technical Paper에 있으니 이 논문에서 따로 설명하지 않는다고 한다. 대신 Hardware-Driven Model Design, 하드웨어와 모델 간의 상호 의존성, 그리고 미래의 하드웨어 개발 방향을 주로 다루고 있다.
2. Design Principes for DeepSeek Models
DeepSeek-V3의 기본 설계 방향이다.
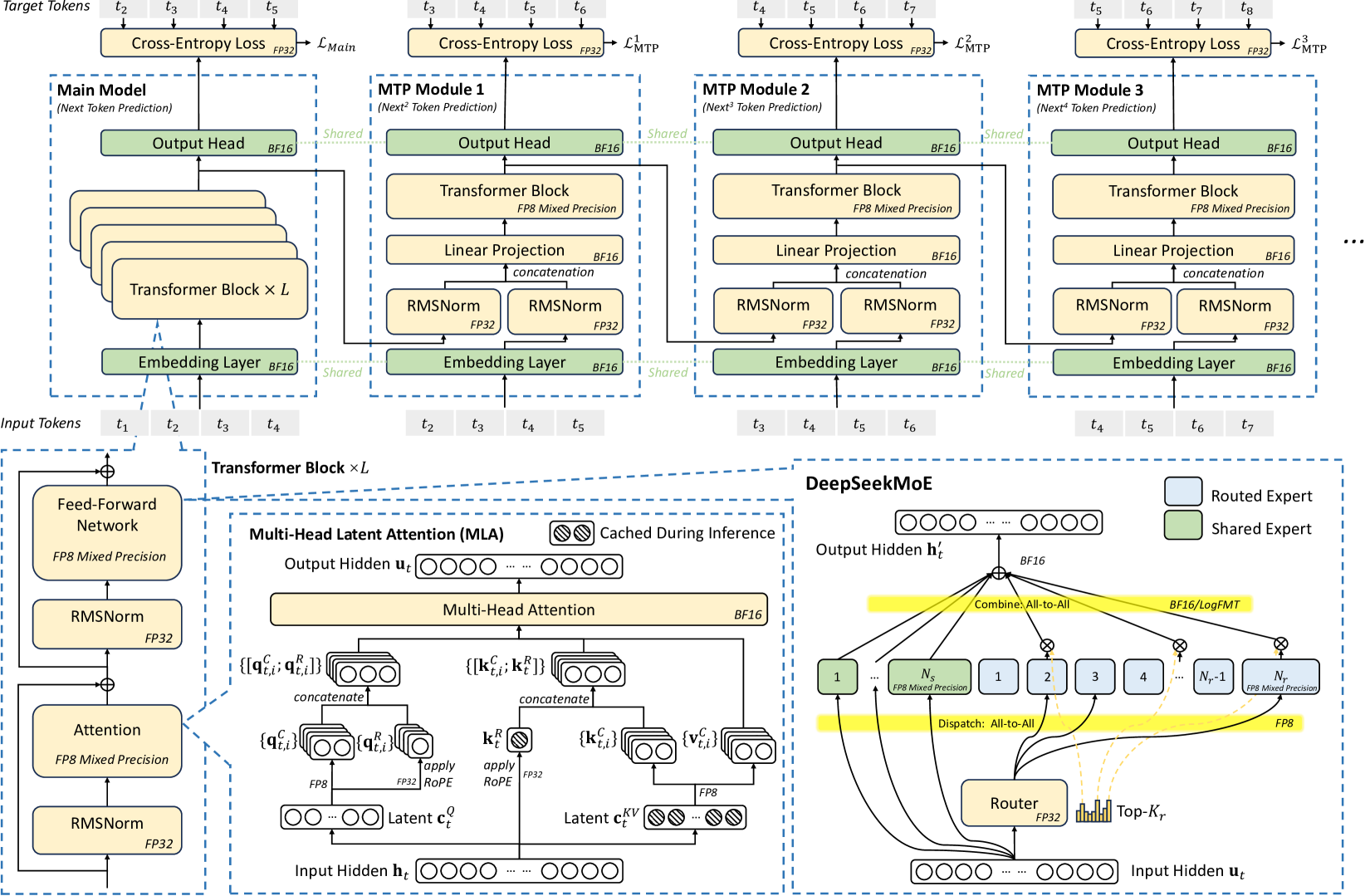
- 자체 개발한 DeepSeek-MoE 구조와 Multi-head Latent Attention(MLA)이 보인다. MLA는 KV 값을 저장할 때 down-projection matrix를 이용해서 압축하고, 사용할 때는 up-projection matrix를 써서 다시 복원하는 방식이다. 자세한 내용은 technical paper를 참고하자.
- 디코더 모듈은 Multi-Token Prediction Module를 사용했다. 이때 inference 속도를 높이기 위해 기존의 3-layer Fat-Tree 대신 Multi-Plane two-layer Fat-Tree 토폴로지를 새로 도입했다.
2.1 Memory Efficiency
메모리 수요는 1년에 1000% 가까이 늘어나는데 고속 메모리 (e.g. HBM) 용량은 훨씬 느리게 증가한다. 때문에 소스에서 메모리 사용 자체를 줄이는 설계가 필요하다.
2.1.1 Low-Precision Models
- BF16 대신 FP8을 사용했다.
2.1.2 Reducing KV Cache with MLA
추론 시에 쓰는 KV 캐시를 압축시키고 다시 복원할 수 있는 projection matrix를 사용했다. 그 외에도 기존에 제시된 KV 캐시 절약 방법이 논문에 간단하게 소개되어있다. 나중에 따로 공부해야지
- Shared KV: GQA, MQA에서 사용되는 기법이다. KV 쌍을 각 어텐션 헤드마다 두지 않고, 여러 헤드가 하나의 KV 쌍을 공유한다.
- Windowed KV: 긴 시퀀스에서 최근 구간의 KV만 유지하고 나머지는 버린다. 당연히 긴 컨텍스트에서 성능이 떨어진다.
- Quantized Compression: KV를 양자화 시킨다.
2.1.3 Future Directions and Perspectives on Resource-Efficient Techniques
아무리 KV 캐시를 효율적으로 저장하려 해도 autoregressive 디코딩 특성상 컨텍스트가 길어질수록 부담이 커진다. (계산 시간 복잡도가 O(N^2)) 여기서는 계산량을 줄이는 최근 연구 방향 두 개를 소개했는데 첫 번째는 Mamba-2, Lightning Attention 처럼 linear한 시간 복잡도를 가지는 알고리즘, 두 번째는 sparse attention을 사용해서 KV를 압축하고 희소하게 활성화하는 것.
여기도 다시 공부해봐야겠다.
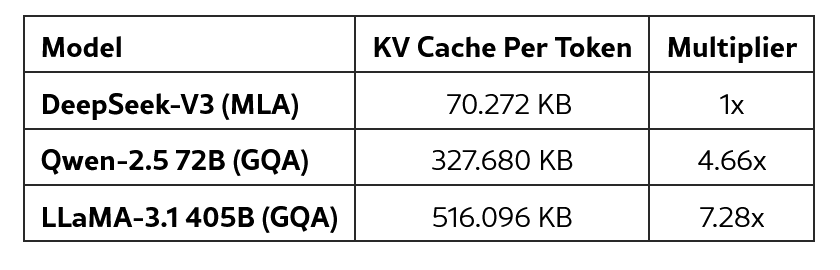
2.2 Cost-Effectiveness of MoE Models
Sparse computing을 위해 DeepSeekMoE를 개발했다.
2.2.1 Reducing Computational Requirements for Training
- DeepSeek-V2는 236B 파라미터에 실제 토큰당 활성화 파라미터는 21B. DeepSeek-V3는 617B, 37B
- Qwen, LLaMa Dense 모델과 비교하면 학습 비용이 압도적으로 적다.

2.2.2 Advantages for Personal Use and On-Premises Deployment
- 로컬 환경에서는 전체 모델에서 일부만 사용하는 MoE가 유리하다. KTransformer 엔진을 사용하면 DeepSeek-V3를 일반 소비자용 GPU(10000 달러 정도) 한 장으로 20 TPS 속도로 추론용으로 사용할 수 있다.
2.3 Increasing Inference Speed
2.3.1 Overlapping Computation and Communication: Maximizing Throughput
Inference에서는 system의 전체 throughput과 단일 요청 latency 모두 중요하다. 이 챕터에서는 throughput을 늘리기 위한 방법을 소개했다.
- 모델을 dual microbatch overlap을 사용하도록 설계해서 계산과 통신을 겹칠 수 있게 했다.
- MLA 계산과 MoE 계산을 두 단계로 분리하고, 한 마이크로배치가 MLA/MoE 일부를 계산하는 동안, 다른 마이크로배치가 dispatch(All-to-All) 통신을 수행한다. 두 번째 마이크로배치가 계산하는 동안, 첫 번째 마이크로배치는 combine 통신을 수행한다. 이렇게 파이프라이닝을 설계해서 All-to-All 통신이 계산과 완전히 overlap되고 GPU 사용 시간이 극대화된다.
- 실제 서비스에서는 prifill과 decode를 각각 다른 EP 그룹 크기로 배치해서 throughput을 늘렸다. (무슨 소리인지... LLM 잘 아시는 분 댓글 부탁드립니다)
2.3.2 Inference Speed Limits
LLM 서비스의 속도는 Time Per Output Token (TPOT)으로 본다. 특히 긴 추론에서는 TPOT이 사용자 경험을 좌우한다.
MoE에서 최고 inference 속도를 내려면 장치당 하나의 expert만 계산하도록 모델을 배치해야 한다. 그 과정에서 Expert Parallelism 라우팅이 필요하고 (각 토큰을 모든 expert에게 보내야 한다) 매 스텝마다 All-to-All 두 번(Dispatch, Combine)을 발생시킨다. 즉 인터커넥션 대역폭이 속도 상한을 결정한다.
논문에서 나온 예시를 보자. CX7 400Gbps 인피니밴드 NIC로 연결된 시스템에서 두 번 All-to-All 통신할 때 걸리는 시간은?

이 계산이 어떻게 나온 걸까? Dispatch 과정에선 FP8, Combine 과정에선 BF16을 사용하고 각 토큰의 hidden size는 약 7K이다. 9는 각 토큰이 8개의 routed expert와 1개의 shared expert로 전달된다는 의미다.
Dual micro-batch overlap을 사용한다고 가정하면 레이어 시간을 두 배로 잡고, DeepSeek-V3에는 61개의 layer가 있으므로 inference time은 61을 곱한 14.76ms로 계산할 수 있다고 한다. 즉 이론상 최대의 TPOT은 14.76ms이고 1초에 67토큰을 출력할 수 있다.
만약 더 빠른 인터커넥트, 예를 들어 블랙웰 아키텍처의 900GB/s NVLink를 사용한다면? 18배 감소한 6.72us의 속도가 된다. 즉 비싼 하드웨어를 쓸 수록 좋은 성능을 얻을 수 있다는 재미없는 결론이 나오는데... 알고리즘 개발 같은 다른 방향을 찾아야 한다.
2.3.3 Multi-Token Prediction
- DeepSeek에서 개발한 프레임워크이다. Inference 동안 기존 autoregressive 방식 모델은 한 번에 한 토큰만 출력한다. 여기서는 메인 모델이 현재 토큰을 계산하는 동안, 보조 모델이 다음 여러 개의 토큰 후보를 선정한다. 그리고 메인 모델은 후보를 검증해서 accpet/reject 여부를 확인하면 된다.
- Acceptance rate가 80~90% 가까이 되기 때문에 TPS를 1.8배 가까이 증가시킬 수 있었다.
2.3.4 High Inference Speed for Reasoning Models and Test-Time Scaling
- Reasoning 과정에서 컴퓨팅 자원을 동적으로 할당해 시간과 성능 사이의 균형을 맞춘다.
- OpenAI의 o1/o3에서도 사용되었고, Claude 3.7 Sonnet, Gemini 2.5 Pro에서도 비슷한 방식을 채택했다.
2.4 Technique Validation Methodology
- MLA, FP8 혼합 정밀도 연산, network co-designed MoE gate routing 등 제안된 방식을 전부 검증했다는 문단
3. Low-Precision Driven Design
3.1 FP8 Mix-Precision Training
FP8 inference 기법은 이전에도 많았고, Nvidia Transformer Engine에서 제한적으로 FP8 학습을 지원하긴 했지만, DeepSeek-V3 이전에는 FP8 학습을 지원하는 대규모 오픈소스 모델이 없었다. 저자들은 FP8 학습 프레임워크를 개발했는데, 단순히 모든 텐서를 FP8로 바꾸는 게 아니라 fine-grained quantization이라는 기법을 사용했다. Activation은 1x128 범위로 양자화하고, weight는 128x128 범위로 양자화해서 저정밀도 범위 문제를 해결하려고 한 것 같다.
3.1.1 Limitations
- FP8 Accumulation Precision: Hopper GPU의 tensor core는 FP8 연산을 지원하긴 하지만, 누적 연산에서 상위 13비트만 남기고 나머지는 버린다. 그리고 덧셈 결과를 FP22 레지스터에 저장하기 때문에 정밀도가 많이 감소될 수 있다.
- Fine-Grained Qauntization Challenges: Dequantization을 위해 scaling factor를 곱하는 과정에서 Tensor core -> CUDA core 통신이 필요하다. 파이프라인이 끊기고 병목이 될 수 있다.
3.1.2 Suggestions
미래 설계자들을 위한 제안이다. 이런 거 좋다.
- 하드웨어 차원에서 Accumulation 정밀도를 FP32 수준으로 늘리거나 사용자가 정밀도를 조정할 수 있는 기능을 추가하면 좋을 것이다.
- 하드웨어가 처음부터 scaling factor를 입력받고 group scaling까지 내부에서 처리할 수 있다면 오버헤드가 크게 줄어들 것이다. 블랙웰 아키텍처에서는 지원한다는 것 같다.
3.2 LogFMT: Communication Compression
통신량 압축을 위한 새로운 자료형이다.
- 타일 내부의 최소값, 최대값에 로그를 취한 다음, 최소값은 S.00...01, 최대값은 S.11...11로 인코딩한다. S는 sign bit다.
- 양자화를 위해 구간값을 구한다. Step = (max - min) / (2^(n - 1) - 2) 로 하고 Step 간격에 맞게 반올림해서 양자화한다.
- 디코딩은 sign bit + exp(min + Step x (K-1)) 공식으로 구할 수 있다.
8비트에서 FP8보다 정확도가 높았고, 10bit에서는 BF16 combine stage와 유사한 성능을 보였다. 하지만 일단 새로운 자료형이기 때문에 Hopper에서 지원되지 않고, log/exp 연산도 비용이 크다. 때문에 실제로는 사용되지 않았다.
역시 하드웨어 구현이 중요하다...
4. Interconnection Driven Design
4.1 Current Hardware Architecture

H800의 특징을 설명하고 있다. 수출 규제에 슬퍼하는 연구진들의 모습이 보인다.
H100과 거의 유사하지만 FP64 연산 성능에 제약이 걸렸고, NVLink 대역폭이 900GB/s에서 400GB/s로 감소했다. 대신 노드마다 8개의 인피니밴드 NIC가 장착되어있다. 이를 최대한 활용할 수 있도록 모델을 설계했다고 한다.
4.2 Hardware-Aware Parallelism
병렬화(https://cheerupbee.tistory.com/5 참고)를 하드웨어 특성에 맞게 사용했다.
- Tensor Parallelism은 GPU 간에 모델을 나눠야하기 때문에 NVLink 대역폭에 직접적인 영향을 받는다. 때문에 학습 단계에선 사용하지 않았고 추론 단계에서 선택적으로 사용했다.
- Pipeline Parallelism을 강화하기 위해 DeepSeek에서 개발한 DualPipe라는 기법을 채택했다. Attention과 MoE 연산을 동시에 실행하며, MoE 통신을 겹쳐서 수행한다.
- 다수의 NIC를 사용해서 All-to-All 통신 속도를 유지할 수 있기 때문에 Expert Parallelism을 적극적으로 사용했다.
4.3 Model Co-Design: Node-Limited Routing
- NVLink 대역폭이 감소하긴 했지만 그래도 IB에 비해서는 굉장히 빠르다(200GB/s : 50GB/s), 때문에 IB 네트워크 사용을 줄이고 intra-node 인터커넥트를 최대한 활용해야 한다.
- DeepSeek-V3에서는 1개의 shared expert, 8개의 routed expert로 토큰을 보내야 한다.
- 만약 이 expert들이 한 노드에만 있다면 IB는 한 번만 쓰고 노드 내부에서 NVLink로 복제해서 전송할 수 있으며 IB 전송 비용은 8t(전문가들이 8개 노드에 분산되어있던 경우)에서 M*t로 감소한다. (M은 노드 수, t는 IB를 통해 1토큰이 전달되는 시간)
- 여기서 M이 일정 이상으로 커지지 않도록 모델을 배치하면 된다. 이를 Node-Limited Routing이라고 부른다.
4.4 Scale-Up and Scale-Out Convergence
여전히 NVLink와 IB 간 대역폭 차이가 크다. 게다가 GPU의 SM을 최대 20개까지 통신에 사용해야 하는데 이걸 연산에 못 쓰는 건 굉장히 낭비다(가뜩이나 성능도 떨어지는데) 추론 시에 EP all-to-all을 RDMA 기반 통신만 사용해서 SM을 아낄 수 있다.
지금은 SM이 통신 작업을 떠맡고 있지만 전용 하드웨어를 추가한다면... 다음과 같은 기능이 있어야 한다.
- Forwarding: IB/NVLink 도메인 간에 같은 노드의 여러 GPU로 갈 트래픽을 집계/분배
- Data Transport: RDMA 등록 버퍼와 입출력 버퍼 사이의 데이터 이동
- Reduce: EP combine 단계에서 reduce 연산
- 메모리 레이아웃 관리
- All-to-All 전후 자료형 변환
논문에서는 하드웨어와 프로그래밍의 프레임워크 레벨을 다음과 같이 통합하자고 제안했다.
- Unified Network Adapter: NIC나 I/O die를 노드간, 노드 내부에 모두 직결되게 설계해서 어댑터가 기본적인 스위치 기능을 할 수 있도록, 예를 들어 노드 내부 GPU에서 노드 외부의 특정 GPU에 패킷을 바로 전송할 수 있도록 하자.
- Dedicated Communication Co-Processor: 패킷 처리를 SM이 아닌 전용 프로세서에서 처리하도록, 추가로 메모리 복사도 하드웨어 가속으로 처리하면 좋을 것 같다.
- 유연한 Forwarding / Broadcast / Reduce 메커니즘: Multicast는 수정해서 dispatch에 활용하고, reduction은 combine에 활용할 수 있도록 유연한 변경이 가능하게
- Hardware Synchronization Primitives: 메모리 acuire/release를 하드웨어에서 처리하도록 해서 소프트웨어 동기화를 줄이자.
4.5 Bandwidth Contention and Latency
지금 하드웨어는 NVLink, PCIe 간의 트래픽 우선순위를 동적으로 제대로 조절하지 못한다. 추론시에는 CPU에서 GPU로 KV 캐시를 전송하기 위해 PCIe를 쓰는데 대역폭이 순식간에 포화된다. 이때 GPU가 EP all-to-all 통신을 하면 PCIe와 IB가 충돌할 수 있다.
여기서도 제안점이 여러 개 있다.
- Dynamic NVLink/PCIe Traffic Prioritization: 하드웨어 차원에서 트래픽 종류별 우선순위를 구별할 수 있도록
- I/O Die Chiplet Integration: NIC를 별도 PCIe로 연결하지 말고 I/O die에 통합한 다음 GPU compute die와 동일한 패키지에 넣기. 충돌이 사라진다.
- CPU-GPU Interconnects within the Scale-Up Domain: CPU와 GPU 간의 인터커넥트를 NVLink 처럼 별도의 고대역폭 네트워크로 연결하기, KV 캐시 전송 시 대역폭/레이턴시 문제가 크게 완화될 거다.
5. Large Scale Network Driven Design
연구분야가 분야인지라 토폴로지 부분을 집중적으로 읽었다.
5.1 Network Co-Design

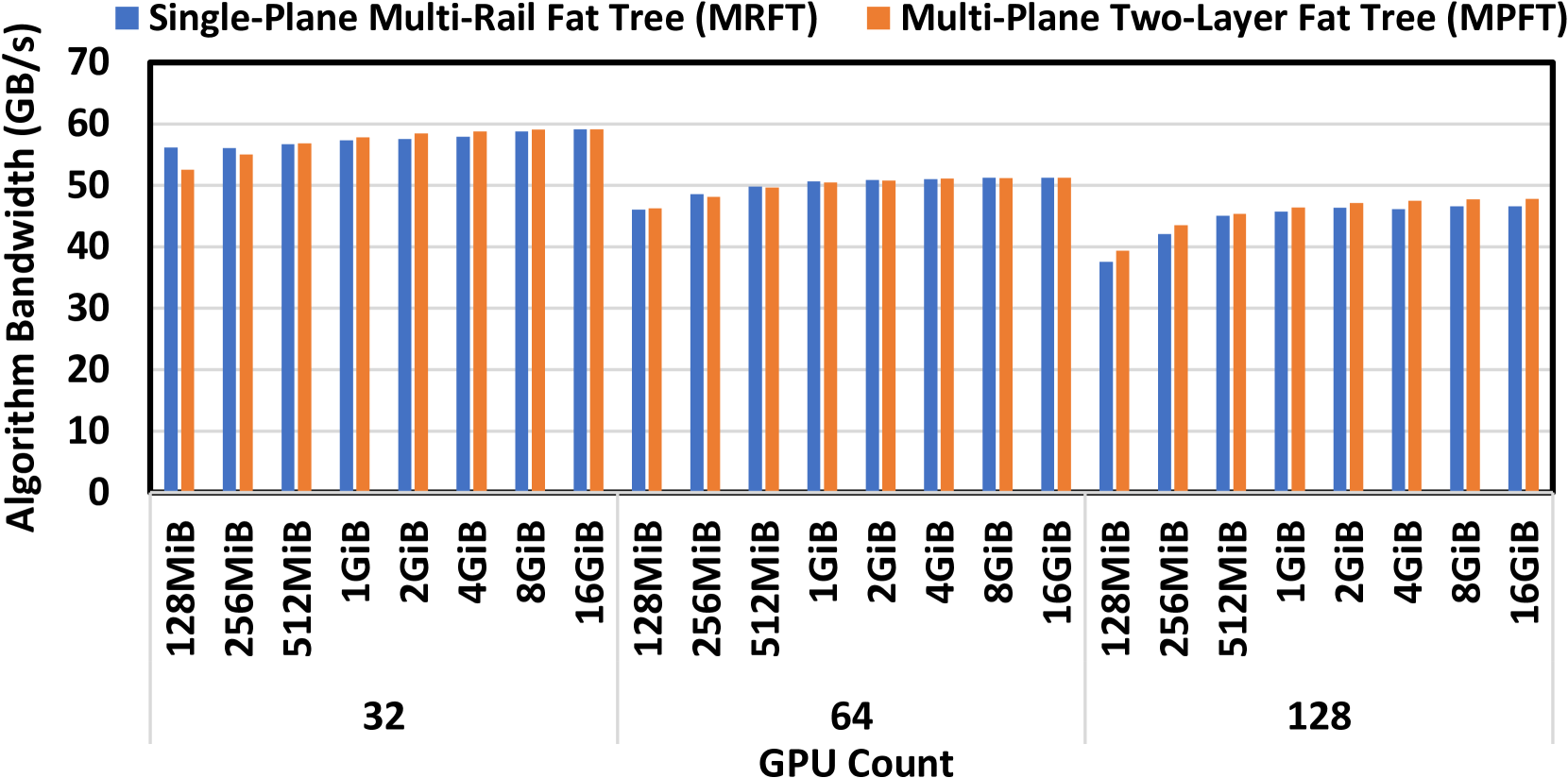
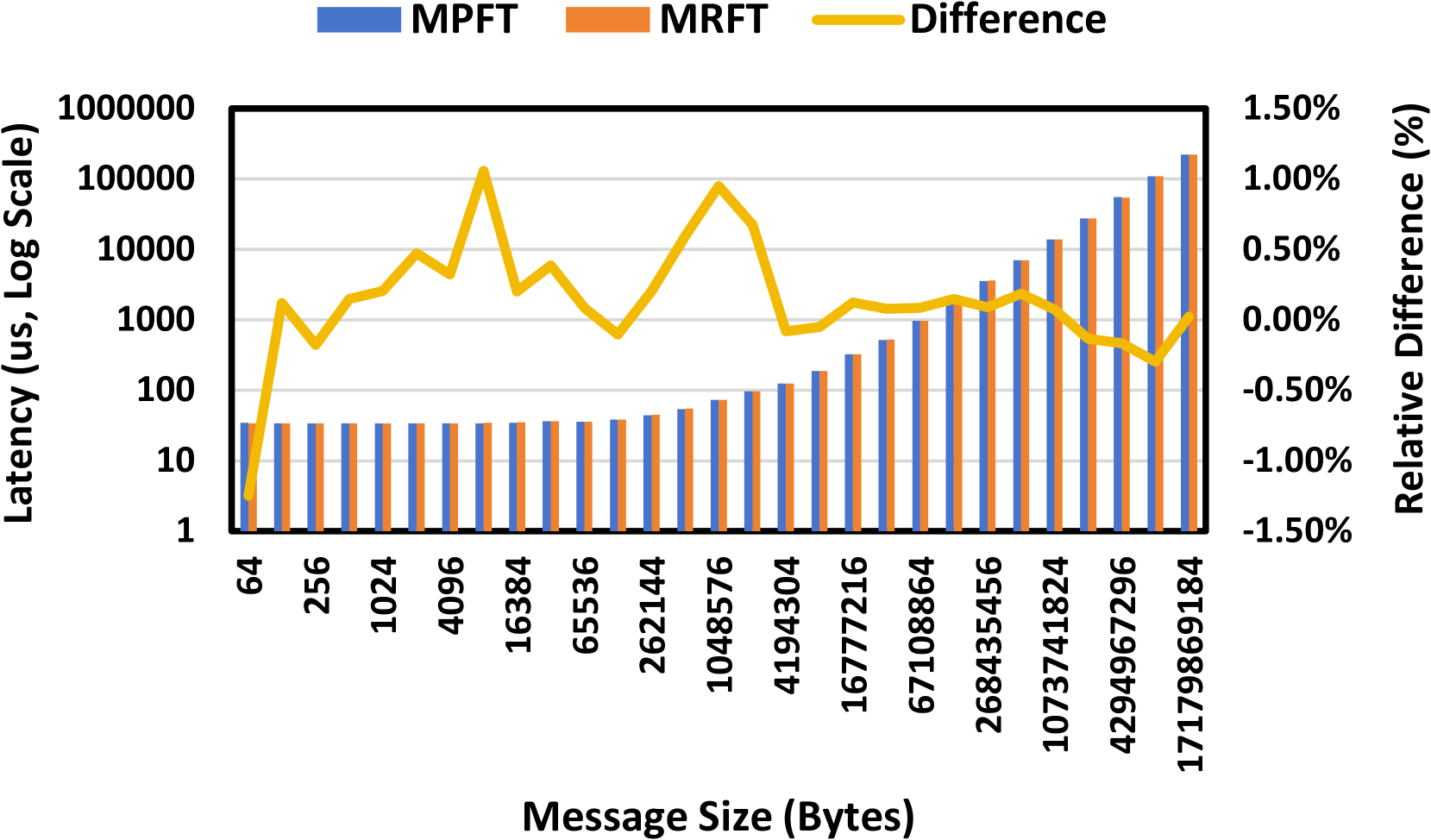
학습 과정에서 Multi-Plane Fat-Tree(MPFT)라는 토폴로지를 scale-out network에 도입했다. 각 GPU-NIC 쌍이 서로 다른 Scale-out network plane에 연결된다. 별도로 각 노드에 400Gbps Ethernet RoCE NIC(그림에서 8번)이 있고 이는 스토리지 전용 plane에 붙어서 3FS 파일 시스템 접근에 사용한다.
새 토폴로지에 이것저것 장점이 있는데
- 기존 Rail-Optimized Fat-Tree의 변형이기 때문에 Nvidia NCCL의 Multi-Rail network 지원을 그대로 쓸 수 있다.
- 2-tier SW만 가지고도 10000개 이상의 터미널 연결이 가능한 구조다.
- 각 plane이 isolation되어 있어 안정성이 높다. 특정 plane에서 장애가 발생해도 다른 plane에 영향을 미치지 않는다.
- 2-tier이기 때문에 latency 면에서 3-tier fat-tree보다 우월하다.


실제로 저자들이 목표로 했던 토폴로지는 NIC 별로 plane을 분리하는 것이 아니라 NIC에서 plane을 선택할 수 있도록 하는 구조다. 이렇게 구현할 경우 단일 포트에 이상이 있어도 우회가 가능하다.
5.2 Low Latency Network
- 앞서 말했듯이 EP 기반의 추론에서는 all-to-all 통신이 성능을 좌우한다. 만약 네트워크 대역폭이 50GB/s라면 이상적인 데이터 전송 시간은 120us이다. 그런데 네트워크 자체의 latency가 마이크로초 단위이기 때문에 이를 무시할 수 없다.
- IB는 항상 RoCE보다 latency가 낮다.
- 단점은 장비가 비교적 비싼 것. 또 IB 스위치는 보통 64포트인데 RoCE는 128포트까지 지원하는 경우가 많아 확장성에서도 불리하다.
RoCE에서 개선할 점을 몇 가지 제안했다.
- 저지연 특수 RoCE 스위치 개발: 이더넷보다 RDMA에 특화되도록 만들기
- 라우팅 정책 최적화: ECMP는 AI 워크로드에서 부하 분산이 비효율적이다(다른 논문이지만 Alibaba HPN 논문에서도 언급되었었다). 새로운 정책을 만들어야 한다.
- 트래픽 격리, 혼잡 제어 강화: Virtual Output Queuing, RTT 기반 CC, 사용자 정의 CC 등을 언급했다.

DeepSeek에서는 InfiniBand GPUDirect Async(IBGDA)를 채택했다. GPU가 CPU Proxy Thread를 호출하지 않고 직접 RDMA를 제어한다. 병렬 제어가 가능하고 덕분에 작은 메세지 크기에서 강점을 가진다.
6. Discussion and Insithgts for Future Hardware Architecture Design
미래의 하드웨어 아키텍처 설계를 위한 문제와 해결책 제안들이다. 위에도 많았지만 누군가를 위해서 방향을 제시한다는 건... 나에겐 아직 꿈이다.
6.1 Robustness Challenges
한계점
- IB나 NVLink 같은 고성능 인터커넥트는 단시간만 끊어져도 학습이 크게 지연되거나 실패한다.
- 노드나, GPU나, ECC 에러가 학습 중에 한 군데에서만 나도 전체 시스템을 재부팅해야 할 수 있다. 규모가 커질수록 고장 확률은 커진다. (독립시행...)
- ECC가 못 잡는 오류들(Multi-bit flip, 계산 오류)가 모델을 아무도 모르게 망가뜨릴 수 있다. 지금은 application level에서 휴리스틱하게 잡아야 하고 시스템 전체적인 신뢰성을 보장하기엔 부족하다.
제안점
- ECC보다 더 강력한 에러 탐지 기법, 하드웨어로 중복 연산해서 검증하기
- 하드웨어 벤더가 신뢰성을 위해 진단 툴킷을 기본 제공하는 게 좋을 거라고 제안하고 있다.
6.2 CPU Bottlenecks and Interconnects
- 4.5에서 봤듯이 지금 대부분의 CPU-GPU 연결은 PCIe 기반이다.
- 파라미터, 그래디언트, KV 캐시 전송시 특히 병목이 뚜렷하게 나타난다.
- 역시 4.5에서 나온 얘기지만 고대역폭 인터커넥트를 새로 만들어 CPU와 GPU를 같은 scale-up 도메인으로 통합해서 intra-node 병목을 제거해야 한다.
- PCIe 5.0 x160 lanes 대역폭은 640GB/s이다.
- 이를 메모리가 감당하려면 1TB/s 대역폭이 필요하다. 기존 DRAM으론 불가능하고 CPU에도 HBM이 필요하다.
6.3 Toward Intelligent Network for AI
Latency-sensitive workload 수요를 감당하기 위해 latency 감소, intelligent network에 초점을 맞춰 제안한 내용들.
- Co-Packaged Optics: Optical network를 스위치/가속기에 통합해서 훨씬 높은 대역폭, 낮은 전력을 가져가기, 기존 electrical interconnect에는 한계가 있다. (TPU v4 논문에서도 OCS를 사용했다)
- Lossless Network: Credit-Based Flow Control로 무손실 전송이 가능하지만 HoL Blocking 문제가 있다. 기존 흐름제어 방식에서 벗어난 endpoint-driven CC, GPU/NIC가 스스로 네트워크 상태를 감지하고 전송 속도를 조절하는 방식이 필요하다.
- Adaptive Routing: 실시간으로 네트워크 상태를 모니터링하고 패킷을 여러 경로로 spraying하는 방식이 필요하다.
- Efficient Fault-Tolerant Protocols: Self-handling protocols, redundant ports, rapid failover, link-layer retry, selective retransmission 같은 기법을 통한 빠른 장애 복구
- Dynamic Resource Management: 하드웨어 수준에서 트래픽 우선순위를 할당할 수 있도록, 예를 들어 추론 트래픽을 학습 트래픽과 격리하고 latency-sensitive app에 우선순위를 주고...
6.4 Discussion on Memory-Sementic Communication and Ordering Issue
- Memory-semantic: Load/store 처럼 메모리를 직접 읽고 쓰는 방식
- Message-semantic: Send/recv 기반의 메세지 교환, ordering은 메세지 레벨에서 맞춘다.
- Memory-semantic에서는 store 이후 fenct -> flag update 순서가 반드시 보장되어야 하므로 barrier를 사용한다. 이 과정에서 round-trip time 지연이 생긴다.
- Message-semantic에서도 유사한 문제가 있다. RDMA atomic add와 packet spraying 후 regular write가 뒤섞이면 ordering 문제가 발생한다. 여기서도 순서를 보장하기 위해 RTT 지연이 생긴다.
- 지금은 소프트웨어 기반으로 ordering을 보장하지만, 이를 하드웨어 기반으로 바꿀 수 있을 것이다.
6.5 In-Network Computation and Compression
- EP 통신의 All-to-All은 dispatch/combine으로 이루어져있고 각각 multicast, reduce와 유사하다.
- 기존 in-network computing 구현 (Sharp 같은 거?)은 broadcast, AllReduce 같은 패턴에 맞춰져 있고 위와 같이 작은 규모의 통신은 지원하지 않고 있다. 이를 지원할 수 있으면...
- LogFMT도 네트워크 하드웨어에서 처리하자고 제안했다.
근데 이거... 엔비디아에서 지원 해주려나?
6.6 Memory-Centric Innovations
- DRAM-Stacked Accelerators: DRAM을 3D로 logic die 위에 쌓아 메모리 대역폭과 latency 둘 다 향상시키기. SeDRAM 같은 아키텍처가 있다.
- System-on-Wafer(SoW): 극도로 거대한 모델은 웨이퍼 스케일 시스템이 필요할 수 있다.
- DeepSeek-V3는 HW-SW co-design의 전형적인 예시이다. 하드웨어 한계를 고려하면서 모델 설계와 시스템 구성을 같이 진행했다.
- 차세대 AI 시스템 로드맵을 굉장히 구체적으로 제시하고 있다. AI 가속기를 물어보는 사람이 있으면 이 논문부터 보여주고 싶을 정도다.
- 컴퓨터 시스템, 특히 인터커넥트 쪽에 초점을 맞춘 논문이라 기존 AI technical paper 들과는 많이 다른 느낌으로 읽을 수 있었다.
'논문 리뷰 > 컴퓨터 시스템, 아키텍처' 카테고리의 다른 글
| TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hard (6) | 2025.08.18 |
|---|