https://doi.org/10.1007/978-3-030-50743-5_3
멜라녹스(지금은 엔비디아에 인수된)에서 개발한 in-network computing 기술, SHARP에 대해 다룬 논문.
https://network.nvidia.com/pdf/solutions/hpc/paperieee_copyright.pdf
2016년 SHArP 논문의 후속 논문이다.
3세대 NVIDIA NVSwitch를 통한 멀티-GPU 인터커넥트 업그레이드
오늘날 AI 및 고성능 컴퓨팅(HPC)의 수요가 증가하면서 GPU 간 고속 통신과 함께 더욱 빠르고 확장 가능한 인터커넥트의 필요성도 함께 커지고 있습니다. 3세대 NVIDIA NVSwitch는 이러한 통신 필요성에
developer.nvidia.com
엔비디아의 최신 홍보자료들에서도 Sharp에 대한 언급은 자주 되고 있는 걸로 보아 계속 밀어줄 모양인 것 같다. 그런데 정확히 어떤 식으로 구현되어 있는지는 공개된 자료가 이번 논문을 포함해 한 두개인가 밖에 되지 않는 걸로 알고 있다... 아무튼 Sharp에 대해 이해하려면 이 논문을 읽긴 해야 한다.
1. Introduction
- Mellanox의 InfiniBand switch에 추가된 SHARP에 대한 논문이다.
- 집합통신, 특히 MPI Allreduce 같은 통신에서 병목이 일어나는 경우가 많다.
- 네트워크 스위치에서 연산 일부를 수행하는 프로토콜을 개발했다.
2. Previous Work
기존의 reduction 연산을 위한 소프트웨어, 하드웨어에 관한 내용이다.
- 소프트웨어의 경우 Rabenseifner 알고리즘(Reduce-Scatter 후 AllGather), Ring 알고리즘
- 하드웨어의 경우 기존에는 소규모 벡터 reduction에 관한 구현이 대부분
3. Streaming-Aggregation
- Streaming-Aggregation: Mellanox HDR InfiniBand에서 새로 추가된 기능, 네트워크를 통과하는 데이터를 실시간으로 reduction해서 선형에 가까운 전송 속도를 유지하는 게 목표
- 기존 SHARP는 low-latency를 목표로 했고, 여기서는 작은 메세지에 대해선 latency-optimized, 큰 메세지에 대해선 bandwidth-optimized 알고리즘을 사용하도록 설계했다.
- 스위치가 reduction-tree를 구성해서 각 노드가 자식 데이터를 reduction해서 하나의 벡터로 만들어 부모에게 전달한다.
- 루트는 결과를 다시 자식에게 복제한다.
- CFU(Collective Functional Unit)이 스위치에 내장되어 하드웨어에서 동작을 수행한다.
- Radix 한계를 고려해서 hierarchical 구조를 만들도록 하였다.

- Reduction-tree는 네트워크 초기화 시에, Aggregation-group은 런타임 (MPI communicator 생성 시) 구성되며 이 그룹 단위로 collective communication이 일어난다.
- Aggregation tree는 latency-optimized, bandwidth-optimized 두 개의 타입이 있다.
- 트리는 특정 그룹만 사용할 수 있다.
3.3 Tree Locking
특정 Streaming-Aggregation 트리를 일정 횟수의 aggregation 연산 동안만 독점 사용하는 기능
- 여러 자식 노드에서 오는 데이터 도착 시점이 제각각이라면? -> 버퍼 점유 시간이 낭비된다.
- 집합 내의 프로세스가 lock 요청을 발행 -> 요청이 트리 위로 전파되고 자원을 lock
- 만약 자원이 다른 집합에 의해 잠겨있으면 실패 알림이 root에서부터 밑으로 전파 -> 자원 해제 + 실패 처리
- 비용은 barrier sync 와 비슷하다.
3.4 Reduction Tree
Streaming-Aggregation reduction-tree는 low-latency reduction-tree와 매우 유사하다.
- 각 Aggregation Node가 여러 child로부터 데이터를 수신한다.
- Reduce를 수행해 하나의 벡터를 생성한다.
- 그룹 내의 Interiror node는 결과를 부모에게 전달한다.
- 그룹의 Root 노드는 최종 결과를 받아 다시 자식들에게 배포한다.
CPU, GPU에서 수행하는 것과 비교했을 때 장점은
- AN이 부모에게 단일 벡터만 전달하기 때문에 상위로 갈수록 트래픽이 급격하게 줄어든다.
- 루트에서 결과를 하위로 보낼 때 AN에서 복제해서 전송한다. 중복 전송할 필요가 없다.
3.5 Reduction Pipelining
긴 벡터를 처리할 때도 고대역폭을 유지하기 위해 파이프라이닝을 도입했다. 파이프라이닝을 위해 송수신 속도를 조절해야 하는데 이는 인피니밴드의 기능을 활용했다.
- IB의 credit-based flow control 매커니즘을 AN에서 data producer에게 버퍼 상태를 알려주는 용도로 사용한다.
- 크레딧 값은 AN이 송신자에게 패킷으로 전달한다.
- 송신자가 크레딧을 다 쓰면 추가로 하나의 "limited" 패킷만 더 보낼 수 있다.
- IB에서 end-to-end credit handling과 동일하다.
3.6 Switch-Level Reduction

- AN이 자식 포트에서 데이터를 받아 지정된 목적지로 전달한다.
- 자식과 물리 포트 사이는 1:1 매핑된다.
- 스위치 포트는 두 개의 half-ring으로 배치되고 중심에서 합쳐진다.
- 최상단 CFU가 최종 결과를 생성해서 상위 노드로 전송한다.
- 데이터는 MTU 단위로 공급되기 때문에(?) 파이프라인을 효율적으로 구성할 수 있다.
위 그림에 나온 예시대로 16-radix switch에서의 reduction 과정을 따라가보자.
붉은 화살표: AN의 자식
원: 두 포트에서 데이터를 받는 Streaming-Aggregation reduction unit
오각형: 최종 결과를 출력하는 CFU
- 왼쪽 branch는 5단계이다. 포트 1, 2에서 들어온 데이터가 C1에서 합쳐진다.
- 결과가 C2로 전송되고 포트 3, 포트 4와 차례로 결합된다.
- C3에서 포트 5와 결합되어 C4로 전달되고, C4에서 포트 8과 결합된다.
오른쪽 branch도 똑같은 과정으로 진행된다. C4, C7의 결과가 CFU에서 합쳐지고 다음 AN으로 출력된다.
3.7 Result Distribution
Reduction이 root에서 끝나면 결과를 배포해야 한다. AllReduce라면 모든 host에 결과를 전송해야 하고, 일반 reduce라면 root만 결과를 받으면 된다. 짧은 메세지에서는 latency-optimized hardware multicast protocol이 데이터 분배에 사용된다. Reliable Connection(RC) 기반 전송으로 신뢰성을 보장한다. 다만 UD 멀티캐스트와 RC를 같이 사용하면 결과가 두 번 전송되며 대역폭이 절반으로 줄어든다. 때문에 대역폭을 위한 새로운 reliable broadcast protocol을 개발했다.
- Aggregatio-group 내의 노드 사이는 Unicast 메세지로 데이터를 전달한다.
- 각 스위치의 CFU가 메세지에서 SHARP group handle을 추출한다.
- 로컬 group table에서 해당 그룹의 목적지 포트 목록을 확인한다.
- Reliable packet generator가 데이터를 복제해서 각 포트로 RC 메세지를 전송한다.
- 이 과정이 트리 최하위까지 반복된다.
3.8 Aggregation Protocol Resilience
네트워크에서 발생한 에러는 사용자(application)이 선택할 수 있도록 설계했다. 실패 시 데이터 소스에 알림만 주고 후속 조치는 사용자가 결정한다. 에러 발생시 해당 aggregation tree는 해체되고 호스트 측의 SHARP 스택이 새 네트워크로 재초기화할지 여부를 결정한다. Application 측에서는 다음과 같이 선택지를 가질 수 있다.
- SHARP 리소스를 재초기화하고 계속 사용
- 다른 host 기반 알고리즘으로 전환하고 aggregation 재시작
4. Experiments
벤치마크 쪽은 요약 대신 직접 느낀점만 적어보려고 한다.

- 메세지 크기 8KB 정도에서 SA와 LLT 사이에 교차점이 생긴다.
- LLT와 Host Based 알고리즘의 대역폭이 큰 메세지에서는 거의 같아보인다.

- 여기 나온 실험들은 내 실험 설계에도 참고해야겠다.
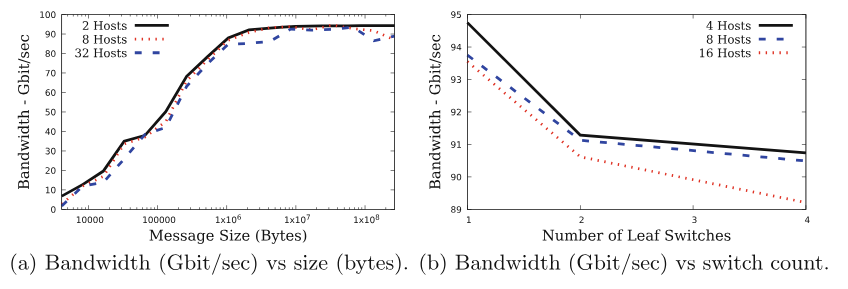
- 호스트 개수가 많아지면 대역폭이 줄어드는 게 눈에 띈다. 스위치 내부 대역폭 문제겠지?
- 클라우드에서 실험할 때는 스위치 개수를 변경할 방법이 없으려나?
- x축 표기는 host 개수의 오타 같다.
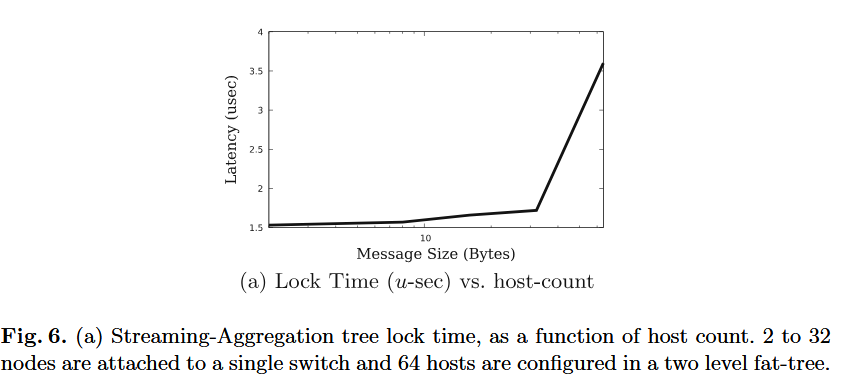
- 단일 계층 스위치에서는 메세지 호스트 수가 커져도 tree locking 시간이 거의 증가하지 않는다.
- Fat-tree 계층이 늘어나면 지연이 증가한다. -> High-radix router가 효율이 좋으려나?
내가 알기론 Sharp에 대한 공개된 논문은 이게 마지막이다. 이후에 NVLink Sharp(NVLS)를 엔비디아에서 홍보하고 있는데 세부적인 작동 방식이 공개되진 않은 걸로 알고 있다. 궁금한 점들은...
- NVLink 같은 고속 인터커넥트에서 스위치에 얼마나 좋은 연산기가 있어야 속도가 충분히 따라올 수 있는지
- NVSwitch에서도 IB와 똑같이 Tree-locking 동기화 방식을 썼나?