https://arxiv.org/abs/2507.04786
NCCL은 굉장히 널리 쓰이는 집합 통신 라이브러리다. MPI와는 다르게 GPU-GPU 통신만을 위해 개발되었고, NVLink, PICe, InfiniBand를 활용해서 고대역폭, 저지연을 목표로 하고 있다.
NCCL은 공개된 정보가 거의 없어서 공식 Github 질문 정도로만 다들 해결하고 있다 이 논문 reference 조차도 몇 개가…. 공식 API 문서로는 내부 구현, 예를 들어서 토폴로지 생성, 알고리즘 선택, 파이프라이닝, 버퍼 관리 같은 것을 제대로 알 수 없다.
이 논문에서는
1. 기본적인 API 구조, 통신 채널 관리
2. 통신 프로토콜 (Simple, LL, LL128) 세부 정보
3. Data-transfer model 분석
4. Collective communication 알고리즘에 대한 종합적인 분석
등을 다룰 것이다.
* 논문에서 NCCL 코드에 나온 함수, primitive, 변수 이름을 그대로 쓴 경우가 많아 이를 기울임체로 따로 강조했습니다.
II. NCCL Overview
NCCL은 Nvidia GPU 클러스터 집합 통신을 위해 설계된 라이브러리이다. NCCL은 사용자에게 크게 네 가지 기능을 제공한다.
A. NCCL API
- Communicator Management
- MPI와 유사하게 모든 통신 작업이 communicator context 내에서 수행된다.
- 모든 디바이스가 단일 프로세서나 스레드에서 관리되면, ncclCommInitAll이 communicator를 만들기 위해 사용될 수 있다.
- 멀티 프로세스나 멀티 스레드 환경에서는 각 프로세스가 ncclCommInitRank를 고유 식별자를 공유한 상태로 호출해서 communicator를 생성한다.
- 통신이 끝나면 communicator은 자원을 적절하게 할당 해제해야 한다. 이를 위해 두 가지 함수를 제공하고 있다.
- ncclCommDestroy: 안전하게 communicator를 파괴하고, 모든 pending 통신이 끝난 걸 확인 후 cleanup 수행
- ncclCommAbort: 즉시 communicator를 중단하고 진행 중인 연산 취소, 데드락 방지, 오류 상황에서 빠른 회복을 위해 사용
- Collective Communication
- 다섯 가지 함수(ncclAllReduce, ncclBroadcast, ncclReduce, ncclAllGather, ncclReducescatter)를 제공한다.
- 과거에는 ncclBcast라는 in-place broadcast 함수가 있었는데 MPI_Bcast 함수와 유사하게 항상 in-place로 동작했다. 현재는 deprecated 되었다.
- Point-to-Point Communication
- ncclSend, ncclRecv 함수를 제공한다.
- Group Calls
- 각 호출마다 오버헤드를 줄이고 독립적인 전송을 위해서 그룹 내부 연산을 동시에 실행하는 기능을 지원한다.
- ncclGroupStart와 ncclGroupEnd로 표기한다.
B. Launching Strategies
- CPU 프로세스 하나당 GPU 하나를 담당하기
- 각 GPU를 분리된 프로세스에 붙인다.
- 프로세스를 NUMA 노드(local CPU)에 붙여서 실행 가능하다.
- 메모리 접근 지연이 최소화된다.
- CPU 스레드 하나당 GPU 하나를 담당하기
- 한 CPU 프로세스가 여러 GPU를 멀티 스레드를 사용해 담당한다.
- 프로세스 내부 메모리를 직접 효율적으로 공유할 수 있다. (프로세스 내부 포인터를 다른 스레드가 사용할 수 있으니까?)
- GPU buffer를 cross-rank로 접근할 수 있으며 통신 과정에서 메모리 복사 오버헤드가 줄어든다.
- CPU 스레드 하나가 여러 GPU를 담당하기
- 한 스레드가 여러 GPU를 순차적으로 관리한다.
- 간단하고 CPU 오버헤드가 가장 적다.
- Deterministic 하게 실행되기 때문에 소규모, 프로토타입 환경에서 구현하기 쉽다. 대규모 환경에선 성능 때문에 부적합하다.
C. Communication Channels
- NCCL에서 통신은 세 가지 하드웨어를 걸쳐 일어난다. GPU, CPU, 그리고 NIC
- GPU: Reduction, 버퍼 간 데이터 이동
- CPU: 커널 런치, 호스트 측 관리
- NIC: 노드 간 패킷 전송
- 단일 SM이 모든 전송을 담당하면 큰 메시지일 때 특정 SM이 과부하되고 다른 SM은 놀게 된다. SM에서 병목이 일어나면 NVLink나 InfiniBand 대역폭을 포화시킬 수 없다. 때문에 NCCL에선 메시지를 여러 개로 나눠 여러 communication channel로 병렬 실행한다.
- Communication channel의 특징은 다음과 같다.
- 각 채널은 하나의 CUDA block이고 각각 독립된 SM에서 실행된다.
- 각 채널은 input buffer를 chunk 단위로 나눠서 서로 다른 영역을 담당한다.
- NVLink 환경에서 각 채널이 다른 NIC로 빠져나가므로 링크 활용률, idle time, 전체 네트워크 부하에서 이점이 있다.
- 채널을 너무 잘게 쪼갤 경우 네트워크 효율성에 문제가 생길 수 있다.
- 청크 크기가 NIC transport FIFO buffer(512 KiB) 보다 작다면 버퍼가 다 채워지지 않은 채로 전송된다.
- 여러 Queue Pair를 ECMP를 위해 사용할 경우 특히 PCIe와 네트워크 성능이 저하된다.
- NCCL에선 작은 메시지에 대해 nChannels 변수를 휴리스틱 하게 작은 값을 사용한다. (enqueue.cc 파일 내의 calcP2pChunkSize 함수 참조)
- 채널 개수는 GPU 병렬성, 네트워크 효율 사이의 트레이드오프를 고려해 결정해야 한다.
- NCCL에서 채널 관리는 communicator 레벨에서 관리한다.
- 각 GPU가 0~n-1(n은 GPU 개수)까지의 rank를 communicator 안에서 부여받는다.
- Collective communication 실행 시 NCCL은 동적으로 알고리즘(Ring, Tree, …)과 프로토콜(Simple, LL, LL128)을 선택한다. 이후 내부 튜닝 모델이 선택된 알고리즘, 프로토콜, 메시지 크기, 가용 대역폭, 채널 당 스레드 수를 고려해서 채널 수를 결정한다.
- NCCL_NTHREADS 환경변수를 변경하면 채널 수를 결정할 수 있지만 현재는 수동 튜닝은 권장하지 않고 있다.
- 채널의 논리적 토폴로지는 각 GPU가 어떤 순서로 데이터를 주고 받을지를 결정한다. 대표적으로 Ring과 Tree 토폴로지가 있다.
- Ring: 각 GPU가 predecessor/successor와 연결되어 unidirectional communication ring을 형성한다.
- Tree: 각 GPU가 parent/child rank로 구성되어 트리를 구성한다.
- NCCL에서는 특히 double binary tree를 채택해서 대역폭 활용을 극대화했다.
(그런데 노드 내부에선 일반 체인이더라고요. 체인도 트리긴 하죠 네...)- Double binary tree가 궁금하신 분은 https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/ 여길 참고하시길 바랍니다
- ncclGroupStart, ncclGroupEnd로 묶인 group point-to-point 연산에서는, 각 전송을 가능한 별도의 채널에 할당해서 여러 송수신을 병렬 실행할 수 있게 한다.
III. Communication Protocols
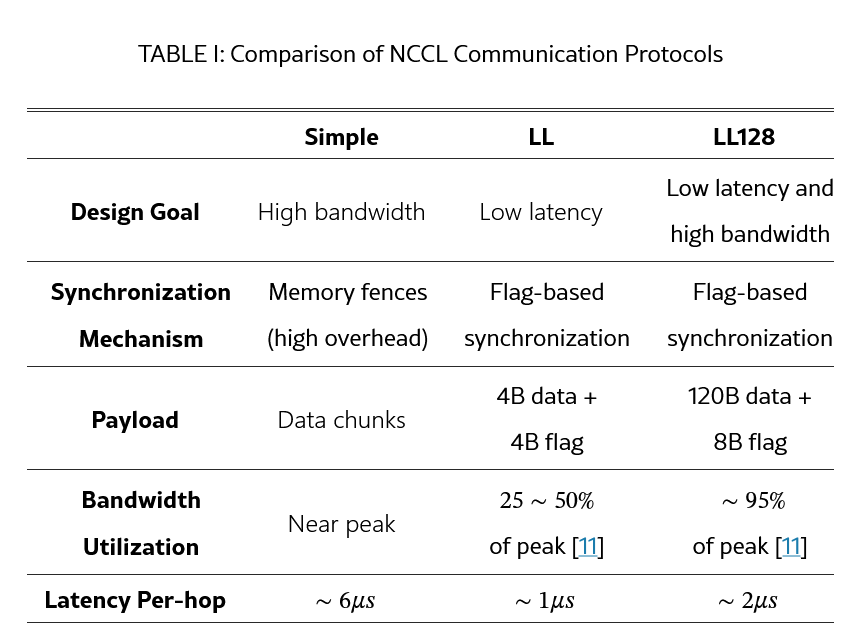
A. Simple
- 대역폭 극대화를 위한 프로토콜이며 큰 메시지 크기에서 사용된다. 큰 메시지를 청크 단위로 나눠 communication channel에 배분한다.
- Memory consistency 문제 때문에 메모리 fence를 사용한다. 수신자는 반드시 모든 청크가 도착한 뒤에 접근할 수 있다. Memory fence는 오버헤드가 있으며, 특히 작은 메세지 크기에서 두드러진다.
- 큰 메시지에서는 최대 대역폭에 가깝지만 작은 메시지에서는 레이턴시 문제가 있다.
B. LL (Low Latency)
- Simple의 높은 latency 문제를 해결하기 위해 설계된 프로토콜, 큰 대역폭이 필요 없는 작은 메세지 크기에서 사용된다. Memory fence 대신 flag-based 동기화 방식을 사용하며, 수신자가 flag를 보고 즉시 데이터에 접근할 수 있다. 4B 데이터 + 4B flag = 8B atomic operation을 이용해 미세 단위로 전송하여 고속 응답이 가능하다.
- CPU가 flag를 polling 해야 하기 때문에 중간 버퍼가 호스트 메모리에 위치해야 한다. GPU memory를 CPU가 PCIe를 통해 polling 하는 건 매우 느리며(DRAM 보다도) 동기화도 추가로 해야 하기 때문에…
- NIC가 GPU 메모리에 직접 접근(RDMA) 하지 못하고 항상 host 메모리를 경유해야 한다. 때문에 인터커넥트에 따라 다르지만 peak bandwidth의 25~50% 정도만 사용할 수 있다.
C. LL128
- LL의 저지연성은 유지하면서 대역폭 효율성을 높이기 위해 설계되었다. LL처럼 flag-based 방식을 사용하지만 8-byte 대신 120B 데이터 + 8B flag = 128B를 전송한다. Peak bandwidth의 95% 정도 대역폭을 활용할 수 있다.
- Simple처럼 큰 chunk 단위로 데이터를 모아 CPU에 전달하며, inter-node 통신에서는 파이프라이닝이 제한적이나 노드 내부에서는 fine-grained pipeline이 가능하다.
- 128B 단위의 atomic write가 가능해야 하며 메모리 시스템이나 인터커넥트가 데이터를 재정렬하면 데이터가 손상될 수 있다. PCIe 기반 등 일부 시스템에서는 지원이 불가능하기 때문에 NCCL이 자동으로 비활성화한다.
D. Protocol Selection and Comparison
- NCCL은 runtime에 다음과 같은 점을 고려해서 Simple/LL/LL128 중에 하나를 선택한다.
- 사용자 설정 (i.e., NCCL_PROTO 환경변수)
- Collective 알고리즘
- 내부 성능 휴리스틱
- NCCL은 튜닝 모델을 사용해서 내부 성능 휴리스틱 요소를 비교하는데, 명시적으로 튜닝 모델을 정하지 않았다면 자체 튜닝 모델을 사용한다. NCCL 내부 튜닝 모델은 다음과 같은 요소를 고려해서 조합을 결정한다.
- 시스템 토폴로지
- GPU 아키텍처
- 메시지 크기
- 사전 정의된 성능지표
- NCCL은 튜닝 모델을 사용해서 내부 성능 휴리스틱 요소를 비교하는데, 명시적으로 튜닝 모델을 정하지 않았다면 자체 튜닝 모델을 사용한다. NCCL 내부 튜닝 모델은 다음과 같은 요소를 고려해서 조합을 결정한다.
- 제약 조건은 가용 자원, 예를 들어 프로토콜에 필요한 버퍼 메모리 등이다.
- 일반적으로 작은 메세지 크기에선 LL/LL128, 큰 메시지에선 Simple이 선택된다.
IV. Data-Transfer Methods and Transport Layer
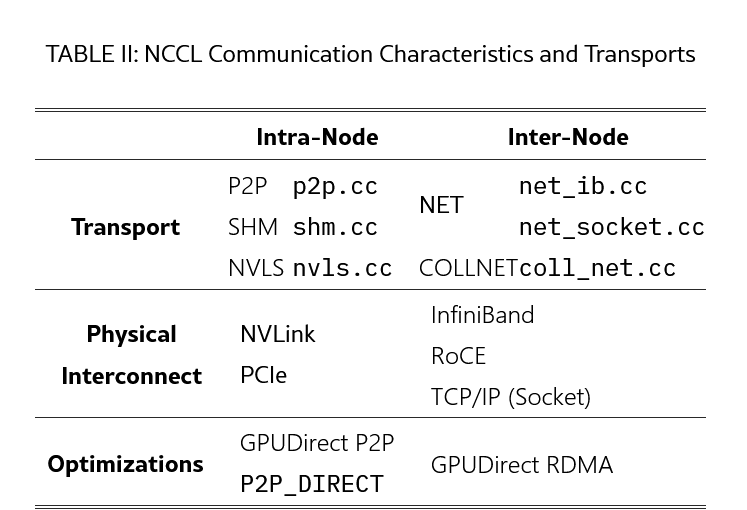
- 통신 성능, 특히 multi-GPU, multi-node에서 효율적인 데이터 전송이 NCCL의 주요 목표이다.
- NCCL에는 노드 내부, 또는 노드 간 통신 각각을 위해서 하드웨어 특성을 감안해 transport를 선택한다.
A. Intra-node Data Transfer

P2P Transport
- GPUDirect Peer-to-Peer 기술을 사용하면 GPU가 CPU 메모리를 거치지 않고 직접 상대 GPU 메모리에 접근할 수 있어 오버헤드가 줄어든다.
- Intra-node 기본 정책은 P2P transport이고 src/transport/p2p.cc 파일 내에 구현되어 있다. NVLink 연결 시에는 GPUDirect P2P over NVLink를 사용하며, NVLink 사용이 불가능할 경우 GPUDirect P2P over the PCIe bus를 사용한다. 이 역시 cudaMemCpy를 이용한 host-memory staging 보다는 빠르다.
- NCCL의 P2P transport에서 핵심 최적화는 P2P_DIRECT mode이다.
- P2P_DIRECT mode는 통신하는 rank가 같은 프로세스에 있을 때 활성화된다.
- 같은 프로세스 주소 공간을 공유하기 때문에 IPC handle이 불필요하고 GPU 버퍼 포인터를 직접 사용할 수 있다.
- 중간 버퍼 없이 directSend, directRecv primitive를 사용하여 직접 송수신이 가능하다.
- 중간 버퍼가 없는 상태에서도 순서 보장을 위해 공유 구조체(ncclSendMem, ncclRecvMem)의 head/tail counter를 atomic operation으로 업데이트해서 전송 순서 유지, 데이터 레이스 방지, 메모리 가시성 확보 등을 보장한다.
참고: atomic operation은 중간에 인터럽트 되거나 다른 연산과 섞이지 않고 한 번에 끝까지 실행되는 게 보장되는 연산을 의미한다.
SHM (Shared Memory) Transport
- GPU 간 direct P2P가 사용 불가능하거나, inter-socket PCIe P2P를 CPU가 처리하는 것이 비효율적이라고 판단되면(특히 GPU가 다른 CPU 소켓에 붙은 경우) 데이터를 시스템 메모리를 통해 우회(PCIe-to-memory, memory-to-PCIe)시키는 SHM transport를 사용한다.
- 한 GPU가 데이터를 shared memory segment에 기록한다.
- 다른 GPU의 프로세스가 해당 shared memory segment에서 데이터를 읽는다.
Intra-node with NICs (Multi-socket system)
- 서버에 여러 CPU 소켓이 있고, 각 소켓마다 GPU가 연결되어 있고, 각 소켓에 NIC가 로컬로 붙어있고, 해당 NIC가 GPUDirect RDMA를 지원한다면?
- GPU→CPU interconnect→GPU 경로 대신 CPU를 통과하지 않는 GPU→PCIe→NIC→NIC→PCIe→GPU 경로를 선택할 수 있다. 이를 사용할지는 NCCL의 topology-aware logic이 자동으로 판단하며 NCCL_CROSS_NIC 환경변수로 제어할 수 있다.
B. Inter-node Data Transfer

- 다른 물리적 노드에 존재하는 GPU 간의 통신을 inter-node communication이라 한다.
- Inter-node communication에서 GPU는 NCCL 커널을 실행한다.
- CPU에서 실행되는 프록시 스레드가 GPU 대신 네트워크를 관리한다.
- Network Fabric이 노드 간에 데이터 전송을 담당한다.
- Figure 2에 나온 것처럼, NCCL이 하드웨어 지원 여부를 보고 TCP Socket transport와 IB Verbs transport 두 경로 중에 하나를 선택한다.
Socket-Based Communication
- NIC가 RDMA를 지원하지 않으면 NCCL이 socket transport를 선택한다. (Fallback)
- Socket transport는 transport/net_socket.cc에 구현되어 있다.
- 중간 버퍼가 CUDA pinned 된 host memory에 위치한다.
- 송신자는 데이터를 GPU에서 버퍼로 기본 socket call을 이용해 복사한다.
- 수신자는 데이터를 host buffer로 받고 이를 GPU로 복사한다.
- PCIe 복사가 두 번 있기 때문에 오버헤드가 크다.
- Rendezvous protocol: 송수신자가 동시에 준비되었을 때만 전송 시작→동기화 비용 발생, 때문에 RDMA에 비해 속도가 느리다.
IB Verbs Transport
- InfiniBand나 RoCE 같은 고성능 네트워크가 지원되면 NCCL은 IB transport를 선택한다.
- net_ib.cc에 구현되어 있다.
- Socket transport와 비슷하게 데이터가 중간 버퍼를 거치지만 버퍼 위치가 하드웨어 지원과 설정에 따라 바뀐다. Rendezvous protocol 역시 데이터 전송 전 송수신자 동기화를 위해 사용된다.
- 기본적으로는 NIC가 GPU 메모리에 직접 접근할 수 없고 중간 버퍼가 host 메모리에 위치한다.
- 송신자 측 GPU 커널이 데이터를 버퍼에 복사하고, 프록시 스레드가 host에서 remote node로 RDMA write 연산을 해야 한다.
- 수신자 측에서는 NIC가 받은 데이터를 host buffer에 write 하고, 프록시 스레드가 host에서 device 메모리로 데이터를 복사한다.
- 프록시 스레드의 역할은 DMA와 RDMA를 관리하는 것이다
- 기본 IB Verbs Transport는 RDMA 기반이라 socket보다 빠르지만 host memory staging에 의한 오버헤드가 여전히 존재한다. 때문에 다음과 같은 최적화가 IB transport에 적용된다.
- The GPUDirect RDMA Optimization
- Host memory staging을 제거하기 위한 핵심 최적화이다
- GPU가 NIC와 같은 PCIe switch에 연결되어 있어야 동작 가능하다.
- 중간 버퍼는 GPU 메모리에 위치한다. CPU 프록시 스레드가 GPU 메모리를 nv_peer_mem, 또는 Linux DMA-BUF subsystem을 사용하여 RDMA-capable NIC에 등록, NIC가 GPU 메모리에 직접 접근할 수 있게 한다.
- NIC의 DMA 엔진이 host memory, CPU 개입 없이 GPU 메모리를 직접 read/write 할 수 있다.
- Per-peer Multi-channel Connections
- 각 remote GPU, NIC 마다 두 개의 논리적 채널을 만들어 충돌을 줄이고 대역폭 활용을 늘린다.
- 각 logical channel은 ncclIbSendComm 구조체를 가지고 있으며, 구조체 내에서 자체 InfiniBand Queue Pair 묶음을 관리한다.
- 실행 중에 호스트 측의 프록시 스레드가 ncclNet→isend()를 호출할 때마다 두 sendComm handle을 라운드 로빈 방식으로 번갈아 사용한다. 즉 QP set들을 통해 트래픽을 분산시킨다.
- 각 QP가 처리하는 chunk가 커지기 때문에 효율적이다.
- ECMP에서 동일한 목적지여도 경로 다양성이 확보된다.
- GPU가 아니라 CPU에서 처리하기 때문에 GPU 측 상태를 확인해야 하거나 오버헤드가 발생하지 않는다.
- QP Layout
- 각 랭크 쌍마다 RDMA 플러그인이 두 개의 reliable connection QP를 서로 다른 방향으로 생성한다.
- Forward QP는 대량 데이터 전송을 담당한다. 여기서 CPU 프록시가 하나 또는 여러 개의 RDMA_WRITE 작업을 요청하면 peer buffer로 데이터를 직접 push 한다. 마지막에는 zero-byte RDMA_WRITE_WITH_IMM을 수행하여 immediate data 필드에 전송 크기를 기록한다. 수신자가 이 필드를 polling 해서 전송 완료를 감지한다.
- Reverse QP는 작은 clear-to-send(CTS) 메세지만 전송한다. 한 번의 RDMA_WRITE로 원격 버퍼 주소, rkeys(remote keys), tag 정보를 전달한다. 한 QP로도 가능하긴 하지만 대용량 데이터가 CTS 메시지를 가로막는 문제(head-of-line blocking)를 해결하기 위해 별도 경로를 만든 것이다.
- Per-peer Multi-channel Connections
- The GPUDirect RDMA Optimization
참고: QP는 IB 같은 RDMA 네트워크에서 통신을 수행하는 기본 단위(Send Queue, Receive Queue 한 쌍), SQ에선 송신 측에서 보낼 작업 요청을 저장, RQ에선 수신 측에서 받을 버퍼를 등록해 둔다. QP가 두 노드 사이의 채널이 된다.
V. NCCL Collective Algorithms

A. Overview of Algorithm and Protocol Support
- Ring, Tree 외에 CollNet, NVLS라는 알고리즘이 보인다.
- CollNet Direct, CollNet Chain은 NVIDIA SHARP 기술을 사용해서 일부 연산을 스위치에서 처리한다.
- CollNet Direct는 노드 내부에서 all-to-all 통신을 지원하고 CollNet Chain은 GPU들을 선형 체인으로 연결해서 reduction은 체인 위로, broadcast는 체인 아래로 전송한다.
(그런데 이거 reference가 NCCL 깃허브 QnA다;;) - NVLS는 NVLink Switch의 SHARP를 사용해 연산한다. 둘 다 intra-node는 NVLink SHARP를 사용하고, 일반 NVLS는 inter-node에서 CollNet과 연계되며, NVLS Tree는 inter-node에서 tree 기반 fan-out을 사용한다.
(이것도 reference가 QnA;;) - 이 논문에선 Ring과 Tree만 살펴볼 것이다.
B. Communication Primitives
- NCCL의 collective 연산은 low-level primitive들의 조합으로 이루어져 있다. 주요 primitive는 다음과 같다.
- send: 데이터 전송
- recv: 데이터 수신
- recvReduceSend: 데이터 수신 → 로컬 버퍼와 reduction → 다음 GPU 전송
- recvCopySend: 데이터 수신 → 로컬 버퍼에 복사 → 다음 GPU 전송
- recvReduceCopySend: 데이터 수신 → reduction → 복사 → 전송
- Direct variants(directSend/directRecv 등): 중간 버퍼 없이 소스 ↔ 목적지 버퍼 직접 접근
- Collective 알고리즘 실행 시, NCCL 런타임이 primitive를 알고리즘, 토폴로지, 전송 계층에 맞게 조합해서 루프(step) 단위로 반복 호출한다.
- Primitive의 동기화 방식, 버퍼 관리 방법, granularity는 protocol 선택에 따라 달라진다.
- Low-level primitive는 Ring, Tree 같은 고정된, 적은 수의 출발지, 목적지를 가지는 집합 통신에 특화되어 있다. (Ring은 출발지 목적지 하나씩, Tree는 최대 3개)
- All-to-All 패턴 같은 경우 출발지 목적지 수가 매우 많아지므로 비효율적일 수 있다.
C. Iterative Execution of NCCL Collectives

- Collective operation이 실행될 때 먼저 사용자 입력 데이터를 communication channel에 나눈다.
- 각 채널은 전체 데이터 중에 연속 구간(contiguous segment)을 담당한다.
- workOffset = 시작 인덱스
- channelCount = 채널이 맡은 요소 개수
Buffers
- NCCL은 프로토콜에 따라 각 채널마다 고정 크기 버퍼를 할당한다(위의 표 참조).
- 이 버퍼는 데이터 전송, 연산을 위한 staging 공간이 된다.
- 각 채널이 담당한 데이터가 총버퍼보다 크면 NCCL이 데이터를 버퍼 크기에 맞게 여러 조각으로 쪼개 Outer loop를 수행한다.
- 한 iteration에서 처리 가능한 크기를 loopCount(버퍼 크기)라 한다.
- 여러 루프를 반복해 전체 데이터(channelCount)를 처리한다.
Slots
- 각 채널 버퍼가 slot으로 분할된다. 일반적으로 8개 슬롯(NCCL_STEPS 환경변수로 설정한다)이고 각 슬롯이 서로 독립적으로 통신/연산 단계를 진행할 수 있기 때문에 파이프라이닝이 가능하다.
- 각 elementary step마다, 슬롯에 chunk를 배정하고, primitive를 실행하고, 완료 후 다음 chunk를 투입한다.
- 채널이 항상 사용되기 때문에 throughput이 늘어나며, 작은 chunk와 여러 슬롯 덕분에 fine-grained overlapping을 구현할 수 있었다.
Elements
- NCCL에서 모든 데이터 전송은 element 단위로 처리되는데 의미는 집합 연산 종류에 따라 다르다.
- AllGather/Broadcast: Element가 1B로 byte 단위 granularity를 가진다. 단순히 데이터를 옮기고 붙이는 역할이므로 데이터 타입에 의존하지 않는다.
- AllReduce/ReduceScatter/Reduce: Element는 사용자 정의 자료형이다. 산술 연산이 필요하므로 타입 크기를 기준으로 element를 결정한다.

- 채널 0에선 workOffset부터 시작해서 전체 데이터를 4개 루프로 나누고, 각 루프마다 2개 element 크기를 가지는 chunk로 나누고 있다.
- 채널 1에선 workOffset 이후 영역을 담당한다.
D. Qualitative Algorithm Analysis
- 모든 NCCL collective 알고리즘은 iterative processing model을 따르지만 GPU가 루프 사이를 파이프라인으로 겹칠 수 있느냐에 따라 두 부류로 나뉜다.
- Non-pipelined: 한 루프의 모든 단계가 끝나야 다음 루프로 넘어가는 알고리즘
- Ring AllReduce, Ring AllGather, Ring ReduceScatter…
- Pipelined: 연속된 루프를 앞뒤로 곂쳐 링크/SM idle 시간을 줄일 수 있는 알고리즘
- Tree AllReduce, Ring Broadcast, Ring Reduce…
- 이 챕터에서는 각 알고리즘의 동작 순서와 특성을 qualitative 하게 비교한다.
- Non-pipelined: 한 루프의 모든 단계가 끝나야 다음 루프로 넘어가는 알고리즘
(1) Non-pipelined Pattern
* k는 집합 통신에 참여하는 GPU 개수이다.
Ring AllReduce

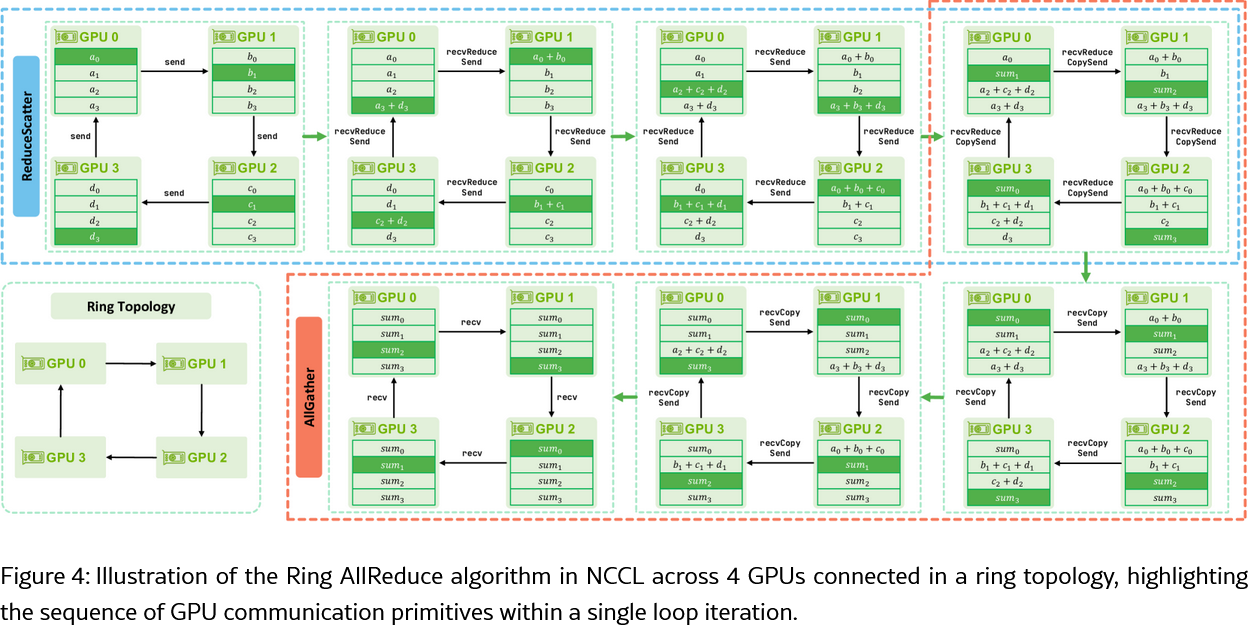
- NCCL에서 Ring AllReduce는 k개의 GPU가 참여할 때 각 GPU가 모든 데이터의 element-wise reduction 결과를 동일하게 보유하도록 한다.
- Step 0에서, 각 GPU가 세그먼트 한 개를 자기 이웃에게 보낸다.
- 다음 k-2 Step 동안 각 GPU가 recvReduceSend 연산을 반복한다.
- k-1 Step까지 왔으면, 각 GPU는 마지막 reduction을 수행해서 결과를 만들었다. 동시에 같은 스텝에서 결과를 복사해서 이웃에게 보낸다.
- Step k ~ Step 2k-2까지는 각 GPU가 recvCopySend를 반복한다. GPU가 reduce 된 segment를 받아 출력 버퍼에 바로 복사하고, 그대로 다음 GPU로 보낸다.
- 마지막 Step (2k-2)에선 각 GPU가 최종 segment를 수신(recv primitive)한다.
Ring AllGater
- Ring AllReduce의 후반부와 동일하다.

- Step 0에서 각 GPU i가 자기 데이터를 준비한다. In-place 연산이면 i번째 segment가 output buffer에 이미 배치된 상태이다. Out-place면 input buffer에서 output buffer로 복사한다(copySend primitive). 이후 각 GPU가 이 블록을 이웃 GPU로 전송한다.
- Step 1 ~ k-2에선 recvCopySend의 반복이다.
- 마지막 Step k-1에선 각 GPU가 마지막으로 recv를 수행하여 블록을 완성한다.
Ring ReduceScatter

- Ring AllReuduce의 전반부와 동일하다. 각 GPU의 sendbuff 안에 k 개의 데이터 블록이 있고 이 블록들이 ring을 돌며 점진적으로 reduce 된다.
- Step 0에선 GPU i가 자신의 데이터 블록 중 하나를 이웃 GPU( (i+1)%k )로 전송한다.
- k-2 Step 동안 각 GPU가 recvReduceSend를 반복한다.
- 마지막 Step k-1에선 마지막 블록을 수신하고 자신의 로컬 블록과 최종적으로 reduce 한 뒤, 결과를 자신의 recvbuff에 저장한다.
(2) Pipelined Pattern
Tree AllReduce
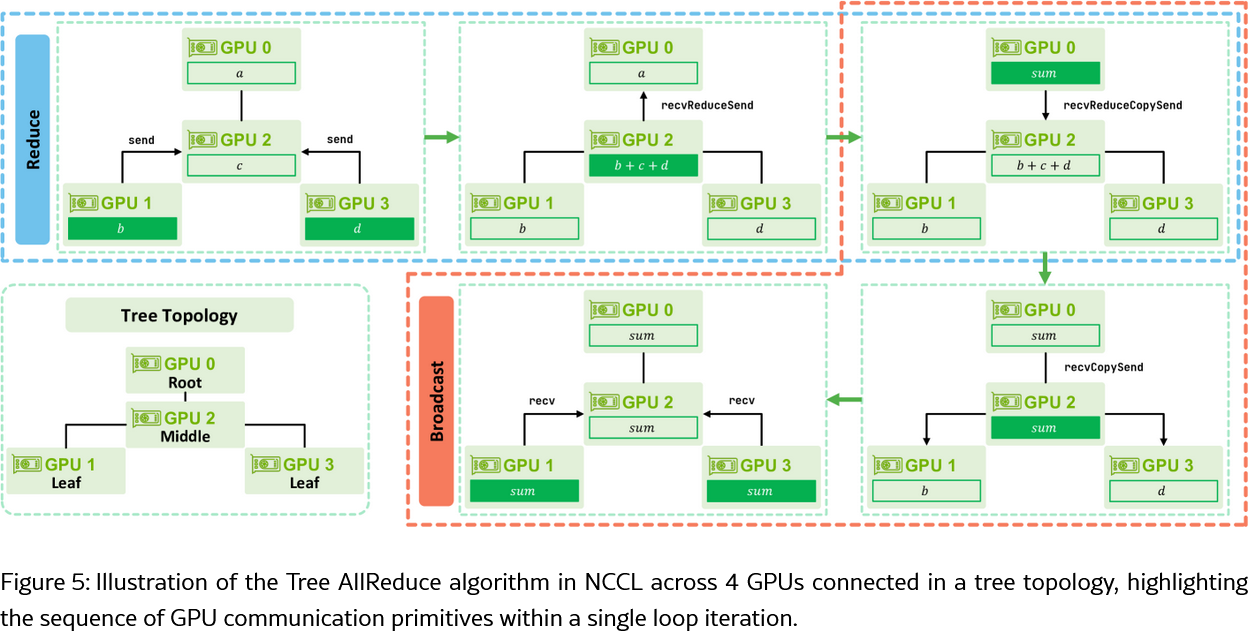

- Pipelined execution pattern을 따른다. 한 loop iteration은 Reduce phase와 Broadcast phase로 이루어져 있다.
- Tree 구조는 inter-node 연결에만 쓰이고, intra-node는 단순 chain으로 구성된다.
- NCCL에선 두 phase가 같이 겹쳐서(overlapped) 실행되기도 한다. 이 경우 SM들이 두 개의 비대칭적인 그룹으로 나뉜다. 더 큰 그룹은 root로 reduction 하고, 작은 그룹은 동시에 root로부터의 broadcasting을 담당한다. Reduction이 더 bandwidth에 민감하기 때문에 비대칭적으로 자원을 할당한다.
- Reduce phase
- Leaf GPU가 자신의 로컬 데이터를 부모에게 send
- Middle GPU는 데이터를 recvReduceSend를 통해 element-wise reduction + forwarding
- Root GPU는 recvReduceCopySend로 데이터를 받아 로컬 데이터와 최종 reduce 후 output buffer에 결과를 저장
- Broadcast phase
- Root GPU는 최종 결과를 자식에게 recvCopySend로 전송
- Middle GPU는 부모로부터 결과를 수신해서 자신의 output buffer에 복사하고 child에게 recvCopySend로 전달
- Leaf GPU는 부모로부터 결과를 recv로 수신해서 output buffer에 기록
Ring Broadcast

- 사용자가 지정한 root GPU 데이터를 communicator 안의 모든 GPU에 복사하는 연산.
- 논리적 토폴로지는 Ring이지만 실제 동작은 root에서 시작해 마지막 GPU까지 이어지는 단방향 chain이다.
그럼 Tree라고 해도 되잖아- Root GPU는 In-place인 경우(sendbuff==recvbuff) 바로 send, out-of-place인 경우 copySend
- Middle GPU는 recvCopySend로 이전 GPU에서 데이터를 수신해서 자신의 recvbuff에 복사한 다음 같은 데이터를 다음 GPU로 전송한다.
- 마지막 GPU는 recv로 자기 recvbuff에 복사한다.
- 단순한 파이프라인 구조이고 hop 수가 많아서 latency가 크지만 안정적이라고 하네요.
Ring Reduce
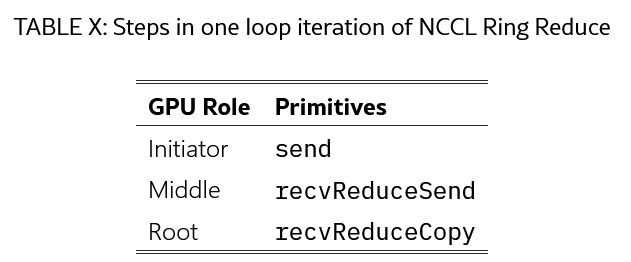
- 역시 단방향 chain이고, 여러 GPU에 분산된 데이터를 element-wise reduction 해서 최종 결과를 root GPU에 저장한다.
- Ring Broadcast와 통신 순서가 반대이다. (Root 쪽으로 흐른다)
- Initiator GPU는 데이터를 send
- Middle GPU는 recvReduceSend
- Root GPU는 recvReduceCopy로 결과를 자기 recvbuff에 기록한다.
- 역시 파이프라인 구조이고 latency 특징도 Ring Broadcast와 비슷하다.
E. Benchmarking
벤치마크는 생략... 논문 appendix에 결과가 있다.
VI. Integration Into ATLAHS
- 저자들이 개발한 GPU 통신 패턴 시뮬레이터 (AstraSim과 비교할 수 있는 것 같다)
- NCCL의 동작 패턴을 분석한 덕분에 집합 통신 알고리즘 특성(특히 병렬화 가능 여부)을 제대로 반영할 수 있었고 실제 실행 결과와 5% 이내의 오차를 유지할 수 있었다.
- LLM 시뮬레이션에서 큰 도움이 될 것으로 기대하는 중이다.
VII. Related Work and Outlook
- NCCL, MPI, Gloo 등의 기존 집합통신 라이브러리 관련 연구에 관한 내용이다.
- NCCL의 현재 과제는 adaptability, topology awareness, fault tolerance라고 저자들은 제시했다.
- Blink 라이브러리는 동적인 multiple tree 구성, 토폴로지 활용 등을 통해 NCCL의 Ring, Tree보다 더 나은 성능을 내기도 했다. SCCL 라이브러리에선 집합 통신을 자동 합성, 튜닝해서 수작업(NCCL…?) 보다 뛰어난 성능을 내기도 했다.
- 향후 AI 학습 워크로드가 점점 커지고 장기화될 것이기 때문에 fault tolerance, resilience가 더더욱 중요해질 것이고…
- 미래의 NCCL은 시스템, 토폴로지를 인식하는 더 자동화된 알고리즘 선택, 더 견고한 장애 처리, 차세대 네트워크 패브릭 지원(In-network computing, Smart NIC 등)이 필요할 것이다.
VIII. Conclusion
- NCCL의 구조와 동작을 protocol, transfer, algorithm 면에서 심층적으로 분석했다.
- ATLAHS 시뮬레이터 개발에 활용되었다. (나중에 논문이 더 나오려나?)
- System researcher, network architect, performance engineer들이 병목 분석, 통신 패턴 최적화, 새로운 라이브러리 개발에 활용할 수 있을 것이다.
사실상 업계 표준으로 쓰는 라이브러리임에도 공개된 자료가 거의 없었다. Github에 있는 NCCL의 제일 오래된 버전이 2016년임을 감안하면, 당장 이 논문도 2025년 7월에야 나온 걸, 게다가 멀티 GPU와 집합 통신이 점점 더 중요해지고 있는 걸 생각하면 굉장히 분석할 부분이 많이 남아있다고 생각한다. 당장 이 논문 나오기 전에는 github랑 수상하게 자세하고 친절한 중국 블로그를 찾아야 했다 사실 지금도
컴퓨터 아키텍처와 네트워크는 진짜 파고들수록 더 공부하고 싶어지는 분야다.