
https://ieeexplore.ieee.org/document/4556717
Technology-Driven, Highly-Scalable Dragonfly Topology
Evolving technology and increasing pin-bandwidth motivate the use of high-radix routers to reduce the diameter, latency, and cost of interconnection networks. High-radix networks, however, require longer cables than their low-radix counterparts. Because ca
ieeexplore.ieee.org
2008년에 발표된 대표적인 high-radix 네트워크인 Dragonfly topology에 대한 논문이다. Dragonfly는 일반적인 토폴로지를 넘어 떠오르는 기술(광통신, high-radix router)과 네트워크 특성(패키징, 케이블)에 초점을 맞춰 토폴로지, indirect adaptive 라우팅 문제를 해결하고 실제 동작할 수 있는 라우팅 알고리즘까지 설계한 논문이다. 덕분에 실제로 여러 HPC(Cray XC, Frontier, El Capitan 등)에서 채택되었고, 이후로도 Dragonfly+ 등의 후속 논문과 더불어 여러 high-radix 네트워크, 슈퍼 컴퓨터 논문에서 2025년 현재까지도 꾸준히 인용될 정도로 큰 영향을 미쳤다.
Dragonfly라는 이름은 넓은 그룹 사이를 잇는 좁은 채널이 마치 넓은 몸통과 좁은 날개를 가진 잠자리 같이 생겼기 때문에 붙었다고 한다.
1. Introduction
인터커넥션 네트워크는 슈퍼 컴퓨터 같은 대규모 시스템에서부터 칩 내부의 멀티코어 시스템까지 많은 컴퓨터 시스템에서 중요한 요소이다. 프로세서와 메모리를 어떻게 묶냐에 따라 성능과 비용이 천차만별로 달라진다. 프로세서와 메모리 성능이 계속 증가하면서 통신 속도가 병목이 되기 때문에, 멀티컴퓨터 인터커넥션 네트워크가 원격 메모리 접근의 대역폭, 지연을 결정하게 된다(참고: 2008년 논문이지만 2025년 현재도 똑같이 적용되는 논리이다).
라우팅 기술 발전과 high-radix network의 등장
- 인터커넥션 네트워크는 쓸 수 있는 기술의 성능과 한계를 둘 다 고려해서 설계해야 한다. 기술 발전 덕분에 라우터 내부의 대역폭이 크게 늘어나고 있는데, 이를 포트 하나하나의 대역폭을 늘리기보다 입출력 핀 개수(radix)를 늘리는데 사용하여 고전적인 3D torus 네트워크에서 벗어나 fat-tree 같은 high-radix network가 등장할 수 있게 했다.
- 광통신이 등장하면서 전기적 채널에 비해 장거리 채널 구현이 더 쉬워졌다. 하지만 광섬유는 구리선에 비해 매우 비싸기 때문에 global channel 개수 역시 주요 고려 대상이다.
이 논문에서는 라우터를 group으로 묶음으로서 광채널 기술을 최대한 이용하여 네트워크의 유효 radix를 늘린 dragonfly topology를 제안할 것이다.
Global Channel
인터커넥션 네트워크에서 토폴로지가 비용, 성능을 대부분 결정하고, 네트워크 비용은 대부분 채널 비용이며, 채널 비용의 대부분은 캐비넷 사이를 연결하는 장거리 global 채널이다. 때문에 비용 측면에서 Global 채널의 개수를 줄여야 하며, 동시에 성능 유지를 위해 global 채널을 지나는 패킷의 개수도 줄어들도록 토폴로지를 설계해야 한다. Dragonfly에선 minimal routing 사용시 글로벌 채널을 최대 1번만 거치도록 설계했다.
Virtual Router

Global diameter가 이렇게 작은 네트워크를 구현하기 위해선 매우 큰 radix의 라우터가 필요하다. 노드 개수가 늘어날 수록 diameter를 유지하기 위해 필요한 스위치 radix는 2N^(1/2)에 비례해서 늘어난다. 64 radix router가 나왔고(2009년 기준이지만 2025년 현재 NVSwitch 같은 GPU 라우터도 64~72 포트를 가지고 있다) 128 radix도 현재 기술로 가능하지만 8K-1M node를 지원하는 네트워크를 만들려면 훨씬 더 큰 radix가 필요하다. 논문에서는 이를 해결하기 위해 여러 라우터를 그룹으로 묶어 High-radix를 가지는 Virtual router를 만드는 토폴로지를 제안했다. 이렇게 구현할 경우 global diameter를 유지하면서 global channel 길이는 줄이는 효과를 기대할 수 있다.
Routing
Dragonfly 토폴로지는 global channel에서 load balancing을 위해 adaptive routing이 필요하다. Global adaptive routing (UGAL)이 좋은 선택이 될 수 있다. 다만 Dragonfly에는 목적지 그룹까지 직접 글로벌 채널로 연결되지 않는 source router가 많기 때문에 수정이 필요하다. 기존 UGAL은 local queue occupancy를 라우팅에 사용하는데, 이 논문에선 UGAL의 두 가지 수정 버전을 제안했다.
- UGAL_VC_H
- 최소 경로와 비최소 경로가 같은 로컬 채널을 공유할 때, 둘의 virtual-channel을 분리해서 관리한다.
- 항상 최소 경로가 선택되는 편향을 막고, 글로벌 채널 활용에서의 load-balancing을 향상시켰다.
- UGAL_CR
- 큐 길이만 보는 것이 아니라 credit-round trip latency까지 활용하여 라우팅한다.
- Backpressure 효과를 더 강하게 볼 수 있어 혼잡 감지가 더 우수하다.
2. Technology Model
High-radix network는 네트워크 diameter를 줄이지만 low-radix network에 비해 글로벌 채널 길이가 길어진다. 여기서는 active optical cable로 어떻게 high-radix network를 장거리 케이블과 함께 구현했는지 알아볼 것이다. 또한 다른 토폴로지에 비해 Dragonfly의 케이블 비용이 어떻게 줄어들었는지 볼 것이다.
Packaging Hierarchy
인터커넥션 네트워크는 여러 패키징 계층 구조 안에 위치하고 있다.
가장 하위에는 라우터들이 회로 보드를 통해 연결되어 있고, 회로 보드는 backplane이나 midplane을 통해 연결된다. 한 개 이상의 backplane이 캐비넷 안에 패키징되고, 여러 캐비넷이 전기, 광학 케이블로 연결되어 전체 시스템을 구성한다.
네트워크 비용을 최소화 하려면, 토폴로지가 가용한 인터커넥트 기술과 잘 맞아야 한다.
전기 케이블의 최대 대역폭은 케이블 길이가 길수록 줄어든다. 일반적으로 길이가 보드 내에선 대략 1m, 케이블에선 10m를 넘어선 안된다. 더 긴 길이의 경우 리피터가 필요하다.
광학 케이블은 고정 비용이 높지만 길이당 비용은 전기 케이블에 비해 낮다. 때문에 여기서는 글로벌 케이블 개수를 줄이고 대신 최대한 장거리에 사용할 수 있도록 하였다.
3. Dragonfly Topology
N: Number of network terminals
p: number of terminals connected to each router
a: Number of routers in each group
k: Radix of the routers
k': Effective radix of the group (or the virtual router)
h: Number of channels within each router used to connect to other groups
g: Number of groups in the system
q: Queue depth of an output port
q_ve: Queue depth of an individual output VC
H: Hop count
Out_i: Router output port i
3.1 Topology Description
Dragonfly는 세 개의 계층을 가지고 있다. Router, Group, System.
한 라우터가 p개의 터미널과 연결되고, 같은 그룹에서의 다른 라우터와 연결되는 a-1개의 지역 채널을 가진다. 또 다른 그룹의 라우터와 연결되는 h개의 글로벌 채널을 가진다. 따라서 라우터의 radix는 k=p+a+h-1이 된다. 그룹 내에선 a개의 라우터가 로컬 채널로 구성된 intra-group interconnection으로 연결된다. 각 그룹은 터미널과 ap개의 연결을 가지고, ah개의 글로벌 채널 연결을 가진다. 이렇게 그룹 내의 모든 라우터가 k' = a(p+h)의 radix를 가지는 virtual router를 형성한다. Virtual router의 radix는 매우 높다. k'>>k이기 때문에 global diameter가 매우 작아질 수 있다.
모든 최소 길이 경로가 글로벌 채널을 최대 한 번만 지나기 위한 그룹 수는 최대 ah+1개이다, 최대 크기 dragonfly (N = ap(ah+1))일 때 그룹 간에는 단 하나의 연결만 존재한다. 이때 global channel 개수는 최소한 (ah+1)/g보다 커야 한다. 네트워크 크기가 더 작으면 그룹을 잇는 글로벌 채널 개수가 많아져 부하를 분산시킬 수 있다. a, p, h는 어떤 값이든 가질 수 있다. 그러나 load-balancing을 고려하면 a=2p=2h여야 한다. 이런 구조여야 각 패킷이 두 개의 local channel, 하나의 global channel, 하나의 terminal channel을 지나는 traffic에서 부하 균형을 이룰 수 있다. 다만 글로벌 채널은 비용이 높으므로 로컬 채널, 터미널 채널이 2:1 비율보다 더 많아질 수도 있다.
이렇게 여러 그룹(virtual router)이 연결되어 전체 시스템을 구성하게 된다.

논문에 나온 p = h = 2 (라우터 한 개 당 터미널 노드, 글로벌 채널 개수가 2개), a = 4 (라우터 하나가 그룹 내의 다른 라우터랑 연결되는 로컬 채널 개수가 4개)인 예시이다. 이 논문에서는 intra-group과 inter-group network 모두에 1D flattened butterfly 토폴로지를 사용했다. Radix k = 7인 라우터를 4개 그룹당 4개 사용해서 global radix k' = 16인 라우터를 구성했고, 터미널 노드 개수 N = 72개까지 지원할 수 있게 되었다.
3.2 Topology Variations
Global radix k'는 intra-group 네트워크에서 고차원 토폴로지를 사용하여 증가시킬 수 있다. 또한 이런 토폴로지로 intra-group 패키징 지역성을 이용할 수도 있다.
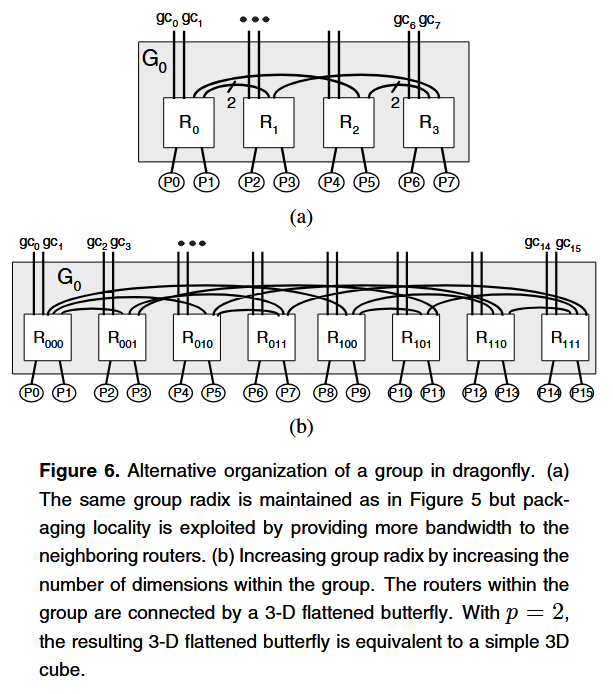
각각 2D, 3D flattened butterfly를 k를 유지하면서 그룹 내부에 적용한 예시이다. 2D에서는 k'가 늘어나진 않았지만 local router 간의 bandwidth가 증가하였다. 3D에선 k'가 16에서 32로 증가하였고 덕분에 N = 1056까지 지원할 수 있게 되었다.
라우터 radix에 영향을 많이 받기 때문에 입출력 포트의 대역폭을 늘리는 것 보다 채널 슬라이싱을 통한 병렬 처리를 가능하도록 하는 것이 좋다. 비슷하게 Dragonfly 네트워크 여러 개를 병렬로 배치하는 구조도 가능하다. 또한 대역폭 균형이 필수가 아니라면 불필요한 inter-group 채널을 제거할 수도 있다.
4. Routing
4.1 Routing on the Dragonfly
Minimal Routing
출발지 그룹 Gs의 라우터 Rs에 연결된 출발지 노드 s에서 목적지 노드 d까지 최소 거리로 라우팅하는 방식이다. 세 단계의 알고리즘을 가지고 있다.
- 만약 Gs가 Gd가 아니고, Rs에 Gd로 직접 연결된 글로벌 채널이 없다면, Rs에서 같은 그룹 내의 Gd와 연결된 글로벌 채널이 있는 라우터 Ra로 전송한다.
- 만약 Gs가 Gd가 아니면, Ra의 글로벌 채널을 통해 Gd 내의 라우터 Rb로 전송한다.
- 만약 Rb가 Rd가 아니면, Gd 내의 목적지 라우터 Rd로 전송한다.
Minimal routing은 트래픽 패턴의 load가 잘 분산되어 있다면 좋은 성능을 보이지만 adversarial traffic에선 성능이 매우 나쁘다. 때문에 Valiant's algorithm 같은 non-minimal routing을 대안으로 사용할 수 있다.
참고: Valiant's routing은 일단 패킷을 무작위 목적지로 전송하고, 이를 다시 원래 목적지로 전송하는 라우팅 방식이다. 왜 이렇게 긴 경로를 사용하냐 할텐데, 트래픽 패턴과 상관 없이 강제로 분산시킬 수 있다는 큰 장점이 있다.
Valiant's Routing
- 만약 Gs가 Gi가 아니고, Rs에 Gi로 직접 연결된 글로벌 채널이 없다면, Rs에서 같은 그룹 내의 Gi와 연결된 글로벌 채널이 있는 라우터 Ra로 전송한다.
- 만약 Gs가 Gi가 아니면, Ra의 글로벌 채널을 통해 Gi 내의 라우터 Rx로 전송한다.
- 만약 Gi가 Gd가 아니고, Rx에 Gd로 직접 연결된 글로벌 채널이 없다면, Rx에서 같은 그룹 내의 Gd와 연결된 글로벌 채널이 있는 라우터 Ry로 전송한다.
- 만약 Gi가 Gd가 아니면, Ry의 글로벌 채널을 통해 Gd 내의 라우터 Rb로 전송한다.
- 만약 Rb가 Rd가 아니면, Gd 내의 목적지 라우터 Rd로 전송한다.
Deadlock

데드락을 막기 위해 virtual channel (VC)를 사용한다. Minimal route에선 두 개의 VC, Valiant's route에선 세 개의 VC가 필요하다.
참고: 데드락을 "푸는" 게 아니라 "회피"하기 위해선 데드락의 원인 자체가 발생하지 않도록 해야 한다. 네트워크에서는 주로 순환성 대기가 일어나는 상황을 제거하게 되며, VC에 번호를 부여해 circular dependency가 끊기도록 설계한다.
4.2 Evaluation
네 가지 라우팅 알고리즘을 Dragonfly에서 시뮬레이션헀다.
MIN, VAL은 위의 챕터에서 설명한 minimal, valiant's routing이며, 추가로 adaptive routing 알고리즘 중 UGAL의 두 가지 방식을 사용하였다.
Universal Globally-Adaptive Load-balanced (UGAL)
UGAL은 패킷 단위로 MIN과 VAL 중 한 경로를 네트워크이 load-balance를 고려하여 선택한다. Queue length와 hop count를 통해 network-delay를 예측하여 더 적은 delay를 가지는 경로를 선택한다.
여기서는 두 가지 UGAL을 구현하여 테스트했다.
- UGAL-L: 현재 라우터의 local queue 정보만 가지고 결정한다.
- UGAL-G: 현재 라우터의 local queue와 같은 그룹 라우터들의 gloabal queue 정보를 모두 가지고 결정한다. 직접 연결되지 않은 라우터 정보를 아는 것은 현실적으로 구현이 힘들다(큐 정보 또한 통신으로 알아내야 한다는 것을 기억하자). 하지만 Dragonfly에선 global channel의 load-balancing이 매우 중요하기 때문에, 여기서는 이상적인 UGAL 구현이라고 가정하고 비교를 위해 테스트했다.
Simulation Settings
네트워크 시뮬레이션에는 cycle accurate simulation을 사용하였다 (참고: 네트워크 시뮬레이터 종류에는 크게 cycle accurate, event driven 두 가지 방식이 있다. 일반적으로 정확도는 cycle accurate 방식이 높지만 시뮬레이션 속도가 느리다). Single-cycle, input-queued router로 구성된 네트워크에 베르누이 과정을 통해 패킷이 주입된다. 라우터가 병목이 되지 않도록 speedup을 충분히 설정했고, flow control의 영향을 제외하기 위해 패킷 크기는 1 flit으로 정했다. 토폴로지는 p = h = 4이고 a = 8인 1K dragonfly를 사용하였다. 버퍼 크기도 기본적으로 16 flits 크기로 설정하고 다른 버퍼 크기도 실험하였다.
Simulation Results

참고: Figure 8은 네트워크 성능 측정에서 흔히 나오는 그래프이므로 모양을 숙지하자. Offered load가 0일 때의 Latency를 zero-load latency라 하고, Latency가 무한대로 발산할 때의 Offered load를 throughput이라 한다.
Uniform random traffic (UR, 대부분의 네트워크에서 이상적인 트래픽이라 benign traffic 이라고도 한다), Adversarial traffic (하나로 정해진 패턴은 없고, Ring에서 tornado pattern 같이 채널 부하가 제일 커지는 트래픽을 말한다. Dragonfly에선 Gi의 모든 트래픽이 Gi+1로 향하는 트래픽을 사용했다.) 두 가지 경우를 실험했다.
UR traffic에선 패턴 자체가 부하를 분산시키므로 MIN이 가장 성능이 높다. VAL은 이미 분산이 잘 된 트래픽을 한번 더 무의미하게 분산시키므로 경로가 MIN에 비해 두 배 가까이 늘어나며 throughput이 절반 가까이 감소한 것을 볼 수 있다.
Adverserial traffic에선 MIN routing을 썼을 때 성능이 가장 좋지 않다. VAL은 이런 트래픽에서도 부하를 강제로 분산시키므로 성능이 유지되고, UGAL-G 역시 VAL 경로를 선택할 수 있으므로 성능이 비슷하다. UGAL-L의 성능이 UGAL-G에 비해 매우 떨어지는 것을 볼 수 있는데 이는 local channel의 정보만 확인하기 때문에 global congestion을 반영하지 못하기 때문이다. 또한 중간 정도의 부하에서 latency가 급격히 오르는 일반적이지 않은 그래프 모양도 보인다. 이 문제는 다음 챕터에서 더 자세히 설명한다.
4.3 Indirect Adaptive Routing
Dragonfly에선 패킷이 어떤 global channel을 지냐나가 성능과 load-balancing에 직접적인 영향을 미친다. 일반적인 네트워크에서는 상대 라우터의 local queue만 보면 채널 혼잡도를 쉽게 알 수 있었다. 하지만 Dragonfly에선 global channel 건너편 라우터 상태를 직접적으로 알기 힘들다(직접 연결된 글로벌 채널이 없다면...) Local channel을 걸쳐 전파되는 backpressure를 통해 간접적으로만 알 수 있고 때문에 adaptive routing에서 문제가 생긴다.
4.3.1 Problem 1: Limited throughput
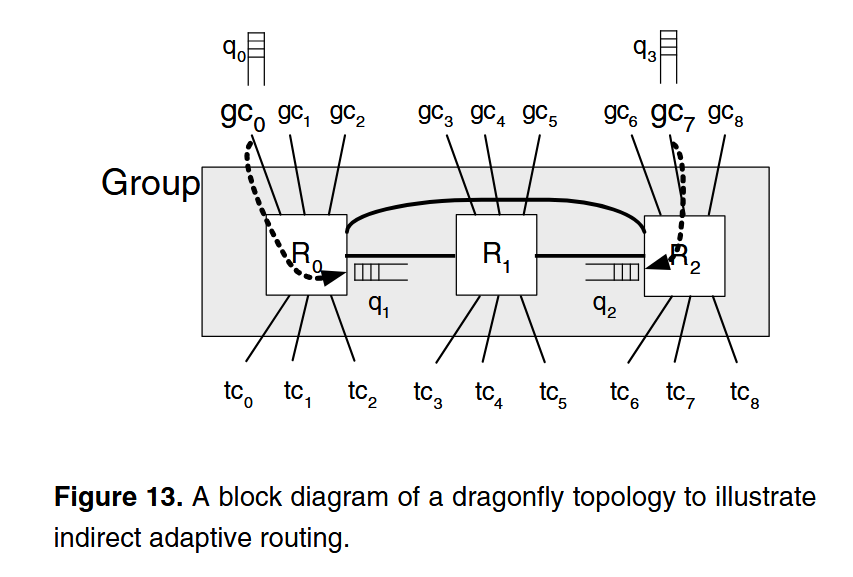
Dragonfly는 특성상 local channel의 대역폭과 개수가 global channel보다 많다. 때문에 local channel로 연결된 큐가 비교적 늦게 차오른다. Local queue가 다 차서 혼잡 신호가 발생했을 때는 이미 global queue가 포화돼버렸을 가능성이 높다. Figure 13이 대표적인 예시인데, R1에서 패킷을 보내려 하고 minimal 경로는 gc7, non-minimal 경로는 gc6이라 하자. 두 경로 모두 패킷이 q2를 지나고, R1은 q2만 고려하는데다, 홉 수는 gc7이 더 짧으므로 "항상" gc7이 선택되고 gc6은 idle 상태가 되어버린다.

Figure 9를 보면 Minimal global channel이 non-minimal에 비해 UGAL-L에서 굉장히 많이 선택되는 것을 볼 수 있다. 이 문제를 해결하기 위해 논문에서는 UGAL을 수정해 minimal path와 non-minimal path의 VC를 따로 고려할 수 있도록 했고 이를 UGAL-L_VC라고 이름 붙였다.

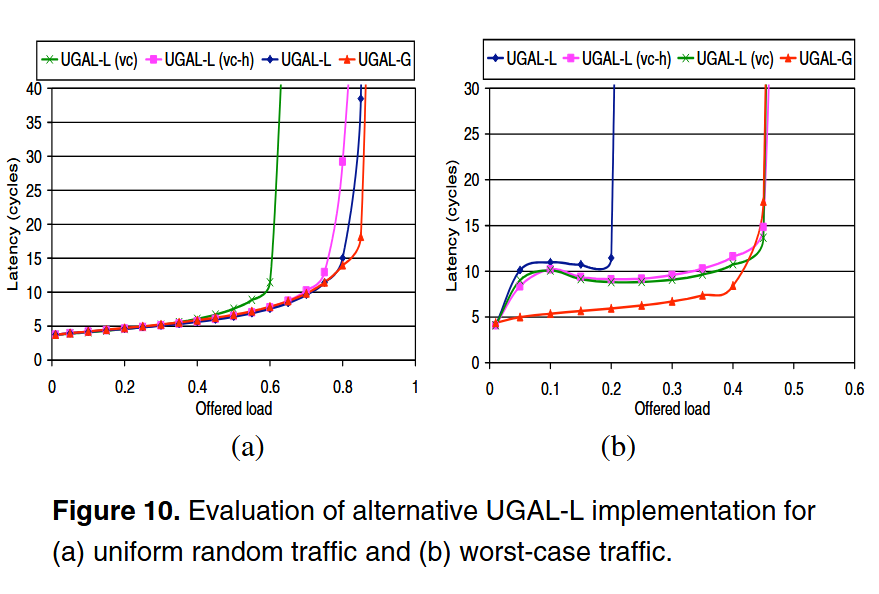
시뮬레이션 결과 worst-case traffic 패턴에서는 UGAL-G 수준의 throughput (이상적인 성능)을 확보했지만 UR traffic에선 throughput이 30% 정도 감소했다. 이유는 WC 상황에서는 대부분의 트래픽이 non-minimal로 가야 하기 때문에 분리된 VC가 효과를 내지만, UR 상황에서는 대부분 minimal 경로가 최선이라 VC 분리가 혼잡을 제대로 반영하지 못한다고 볼 수 있다.

UR에서의 성능 저하를 해결하기 위해 UGAL-L_VC_H (Hybrid) 방식을 추가로 구현했다. 같은 출력 포트일 때는 VC 분리를 적용하고 그렇지 않을 때는 기존 로컬 큐 기반 판정을 유지한다. 시뮬레이션 결과 WC와 UR 모두에서 UGAL-G와 비슷한 throughput을 달성하는데 성공했다. 단점은 UR에서 포화 직전일 때 평균 latency가 UGAL-G에 비해 2배 높았고, WC에선 중간 부하에서 UGAL-G보다 높은 latency를 보였다. (Figure 10 참조)
4.3.2 Problem 2: Higher Intermediate Latency

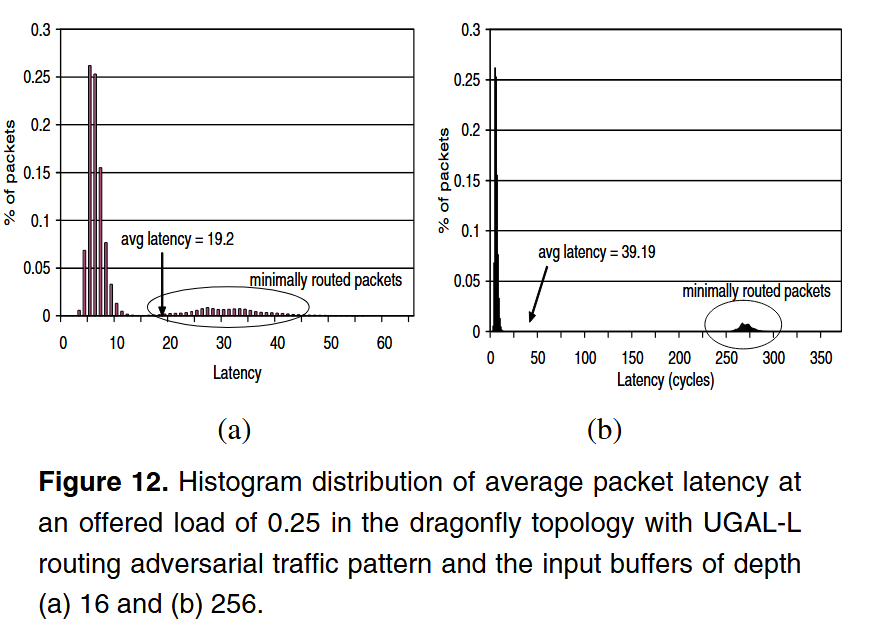
UGAL-L의 높은 중간 latency는 최소 경로로 라우팅된 패킷들이 출발지와 혼잡 지접 사이 채널 버퍼를 혼잡이 감지되기도 전에 채워버리기 때문이다. Figure 11을 보면 min, non-min 경로로 라우팅된 패킷의 latency가 얼마나 걸리는지 나와있다. non-minimal 경로의 latency는 UGAL-G에 가깝지만 minimal 경로에서는 중간 정도의 부하에서 큰 latency를 보이는 것과, input buffer가 커지자 latency가 급격히 커진 것을 볼 수 있다.
Figure 12를 보면 패킷 분포가 저지연, 고지연 두 개로 나뉘는 것을 볼 수 있으며, 나뉘는 정도가 입력 버퍼 크기가 클 수록 커지는 현상을 볼 수 있다.
Figure 13을 다시 보자. 만약 R1이 adaptive routing을 하기 위해 minimal 경로 gc0과 non-minimal 경로 gc7 중에 하나를 고른다면, 글로벌 채널 load balancing을 구하기 위해 글로벌 채널 큐 q0, q3를 알아야 한다. 하지만 q0과 q3의 정보는 R0, R2에서만 직접 알 수 있고, R1에서는 q1, q2만 보고 간접적으로만 알 수 있다. q0과 q3가 모두 꽉 찼다면 flow control은 backpressure 신호를 q1과 q2에 보내 혼잡을 알린다. 즉 가득 찼을 때만 R1이 global channel의 혼잡을 알 수 있고, 뒤늦게서야 non-minimal 경로를 선택하게 된다. 일부 패킷은 이미 혼잡한 minimal 경로로 전송될 수 밖에 없으며 latency가 증가한다.
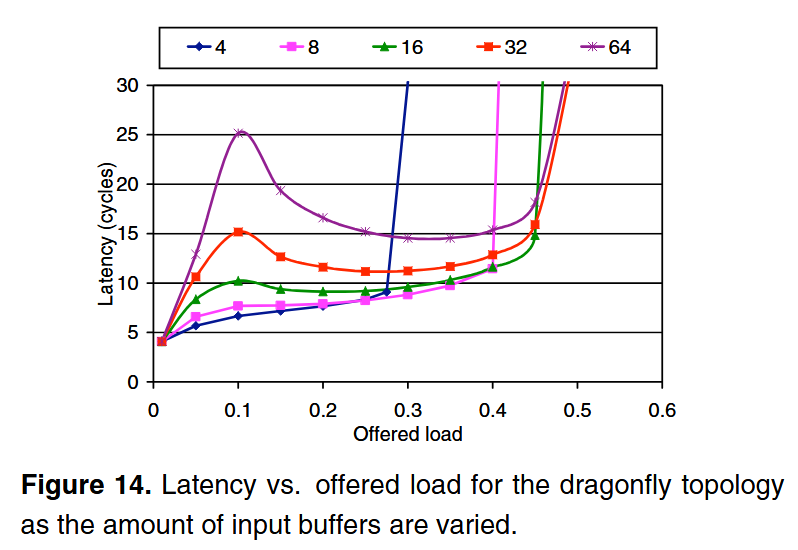
이를 해결하려면 혼잡을 빠르게 감지할 수 있어야 한다. Figure 14를 보면 버퍼를 깊게 할 때 패킷을 많이 저장할 수 있어 throughput을 증가시킬 수 있지만 backpressure 신호가 늦게 발생한다. 버퍼를 얕게 하면 backpressure 신호가 빨리 발생해 latency가 감소하지만 throughput 역시 감소한다.

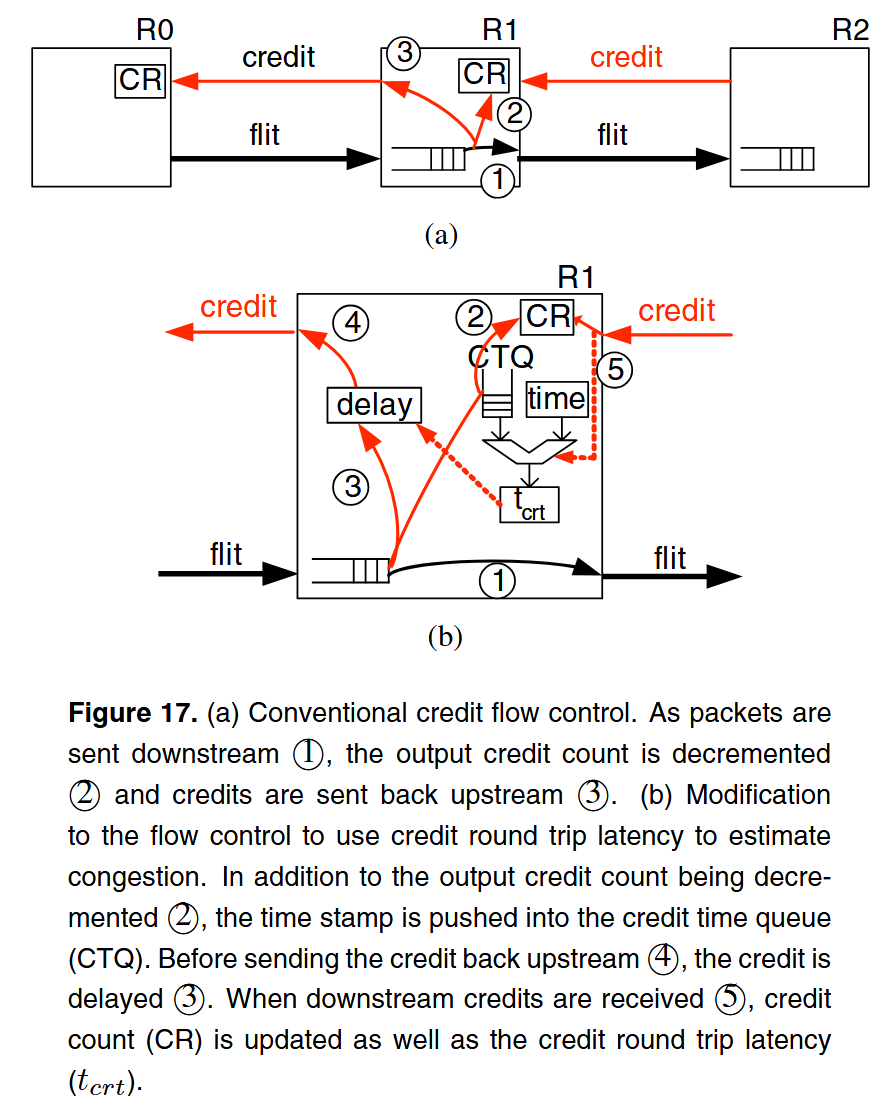
High intermediate latency 문제를 해결하기 위해 혼잡을 빠르게 감지하고 latency를 감소시킬 수 있도록 credit round-trip latency 라는 새로운 측정 지표를 제안했다.
Credit-based flow control에선 각 downstream 버퍼가 credit count를 유지하면서, flit이 downstream으로 전송되면 credit을 감소시킨다. Flit이 처리 완료되면 credit이 upstream으로 반환되며 credit을 증가시킨다.
Credit round-trip latency (tcrt)을 여기서 upstream -> downstream -> 다시 upstream으로 돌아오는 지연 시간으로 정의했으며, Zero-load 상태의 baseline 지연은 tcrt0이라는 값으로 정했다. 혼잡이 발생하면 downstream에서 처리가 지연될 것이고 이때 tcrt > tcrt0이 된다. 각 output O에 대해 혼잡 때문에 늘어난 시간 지연 (time delay)를 td(O) = tcrt(O) - tcrt0으로 구하고 이 값을 기반으로 credit을 delay 시켜 반환한다. 이렇게 하면 upstreasm 라우터가 버퍼가 더 얕은 것처럼 인식하고 혼잡을 더 빨리 감지하는 효과를 낼 수 있다. 글로벌 채널 버퍼에서는 deadlock 문제와 채널 활용이 줄어들 수 있는 문제가 있기 때문에 credit을 지연시키지 않는다.
Credit delay가 너무 커지면 버퍼 크기가 너무 얕아보이게 되고 제대로 활용할 수 없어 throughput이 줄어든다. 때문에 td의 절대값이 아니라 상대적 차이만 delay에 반영할 수 있도록 하였다. 모든 출력 포트의 td(O)를 구하고, 그 중 최소값 min(td(o))를 baseline으로 세워 각 포트의 delay는 td(O) - min(td(o))로 결정한다. 이렇게 모든 포트가 공통 baseline을 유지하면서 혼잡이 더 심한 포트만 추가로 delay를 주는 효과를 낼 수 있다.
하드웨어 추가 구현은 단순하다. 개별 credit을 추적할 수 있도록 flit마다 timestamp를 부여하는 기능, 각 포트당 td(O)를 저장할 수 있는 O(k) 크기의 레지스터, credit 반환을 지연시킬 수 있는 기능이 필요하다.
Credit Timestamp Queue (CTQ)를 사용하여 credit round-trip latency를 쉽게 구할 수 있다. Figure 17에 다이어그램이 있는데, flit 전송 시 현재 시간을 timestamp로 찍고 CTQ tail에 push 한다. 해당 credit이 돌아오면 CTQ head에서 pop한다. push와 pop 시점의 차이가 그 credit의 round-trip latency가 된다.
모든 credit을 추적할 필요 없이 버퍼 크기의 일부만 추적하는 샘플링 방식을 사용하면 하드웨어 오버헤드도 적게 증가한다.
5. Cost Comparison
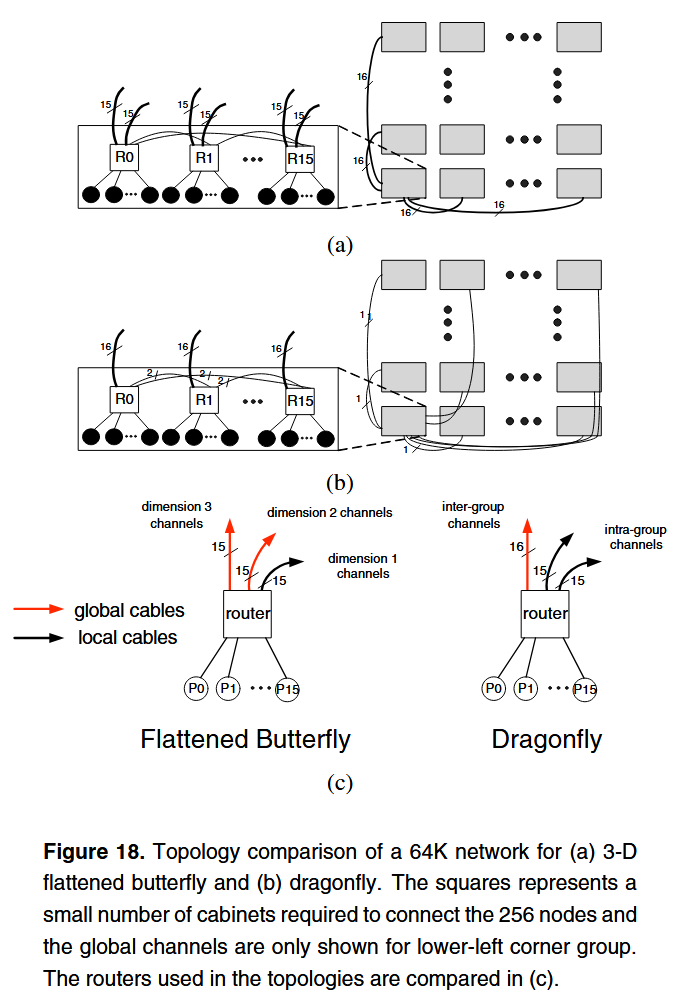

네트워크 비용은 주로 채널(특히 글로벌 채널)에서 발생한다. Flattened Butterfly 토폴로지에선 중간 라우터와 채널을 제거해서 기존 folded-Clos 토폴로지에 비해 50%에 가까운 비용을 절감했다. Dragonfly에선 flattened butterfly의 아이디어를 확장해서 effective radix를 증가시키는 방향을 채택했고 더욱 효과적인 비용 절감과 확장성을 가지게 되었다.
64k node를 기준으로 두 토폴로지를 비교했다. Dragonfly는 그룹 크기가 16 라우터(256 터미널), flattened butterfly는 각 차원 크기를 16으로 설정했다. 64k node를 가지기 위해서는, flattened butterfly는 16 크기를 가지는 두 개의 추가 차원이 필요하다. Dragonfly에선 256 radix virtual router로 모든 그룹을 단일 글로벌 차원에서 연결하는 게 가능하다. 두 토폴로지 모두 global bisection bandwidth는 동일하지만 dragonfly는 절반 정도의 global cable만으로도 충분하다. Flattened butterfly는 50% 정도의 포트를 global 연결에 사용하지만 dragonfly는 25% 정도만 사용한다. 게다가 dragonfly는 그룹 크기를 키워서 확장성을 가져갈 수 있지만 flattened butterfly는 추가 차원이 필요하다. Table 2를 보면 홉 수는 거의 같다. 하지만 dragonfly는 글로벌 케이블 길이가 더 길어질 수록 필요한 케이블 수 자체가 줄어들기 때문에 장거리에서 효율적인 광통신 기술과 잘 맞아떨어지게 된다.

네 가지 토폴로지 (3D-Torus, Folded-Clos, Flattened Butterfly, Dragonfly)의 확장성을 Figure 19에서 비교했다. 8m 미만의 케이블은 전기 케이블, 8m 이상은 능동 광케이블 비용 모델을 적용했고, 라우터는 Dragonfly, Flattened Butterfly, Clos에서 radix-64를, 3D-Torus에선 낮은 radix를 고려하여 라우터 비용을 낮췄다. Dragonfly는 그룹 크기를 512 노드로 설정하였다.
1K 노드 이하에서는 그룹 수가 적고 모든 라우터가 fully connected 되어 1-D flattened butterfly와 Dragonfly가 동일하다. 토폴로지가 fully connected면 virtual router가 비용 면에서 효과가 없고 오히려 비용을 증가시킨다.더 큰 네트워크에서는 dragonfly의 확장성 때문에 글로벌 케이블 수가 flattened butterfly에 비해 적어지며 비용 절감 효과가 발생한다.
3D Torus는 노드 간 거리가 짧아 광케이블이 필요 없다. (참고: 2022년의 TPU v4 논문을 보면 wrap-around 채널에서 광케이블과 광학 스위치를 사용했다) 하지만 diameter가 크고 케이블 수가 많아져 scale을 늘릴 수록 비용이 크게 증가한다.
Clos는 구조적으로 라우터와 케이블이 많이 필요하고 Dragonfly는 항상 50% 이상 비용을 절감할 수 있으며, 케이블 수가 적으면 전력 감소 효과까지 있다.
6. Related Work
1. The Scalable Opto-Electronic Networks (SOENet)
광케이블을 활용하기 위해 여러 subnetwork를 만들고 이를 글로벌 스위치로 연결하는 토폴로지다. Dragonfly와 유사하게 광케이블을 사용하고 그룹 구조를 갖지만 Dragonfly는 high-radix router와 패키징 지역성을 활용한 virtual router 개념을 사용했고 중간 라우터가 없이 flat한 구조를 가지고 있어 diameter가 작다는 점이 다르다.
2. 기존의 hierarchical 토폴로지들은 주로 트리 기반이고 상위 계층으로 갈수록 대역폭에 병목이 있다. 또한 hop 수 증가가 latency 증가로 이어지기 때문에 Dragonfly에선 네트워크 radix를 증가시키는 방향을 채택했고 글로벌 대역폭 증가와 diameter 감소 효과를 가져올 수 있었다.
3. Signaling Technology & Optical Networks
광 인터커넥트는 대역폭이 높고 지연이 낮지만 버퍼링 문제(전기 신호는 메모리로 저장할 수 있지만 광신호는 버퍼 구현이 어렵다) 때문에 구현 비용이 높다. 또한 광 네트워크는 아직 low-radix 스위치를 사용하고 있다(2008년 기준일텐데 현재는 high-radix 구현을 위한 비용이 어느 정도일까요? 궁금하네요). RAPID 아키텍처에서는 수동 광 컴포넌트 기반의 hierarchical 구조를 만들었지만 클러스터 간의 통신에선 latency가 높았고, 수동 네트워크 특성상 확장성에 한계가 있었다.
4. Routing
k-ary n-cube 네트워크에서의 라우팅 연구가 활발하게 진행되어왔다. 송신 큐 기반의 adaptive routing은 throughput 면에서 최적의 효과를 얻지만 intermediate load에서 latency가 높다. 4.3.2 챕터에서 본 결과와 유사하다. Singh의 연구에서는 이를 해결하기 위해 채널 큐를 adaptive routing에 사용했다. 하지만 Dragonfly에선 구조 때문에 channel queue를 사용하기 어렵다. 때문에 이 논문에선 credit round-trip latency를 활용해서 latency를 감소시키는 방법을 제시했다.
시스템 설계는 일부만 보는 것이 아니라 하드웨어 기술, 비용, 패키징, 동작 가능성 같이 모든 걸 통합적으로 고려해야 한다는 걸 다시 느낀다. Dragonfly는 지금 제안되고 있는 구조들에서도 baseline으로 꾸준히 인용되고 있고, 실제 HPC에서도 여전히 활발하게 사용되고 있다.
이렇게 패러다임을 전환하는, 사람들에게 설계 방법을 제시하고 오랫동안 이야기될 수 있는, 기준점이 되는 논문을 쓰는 연구자가 되고 싶다. 아직 정말 공부가 부족하지만... 열심히 할 것이다.